Tribune de Bernardo Cabrera, Directeur de la BU Objenious (Bouygues Telecom).
La e-santé fait parler d’elle depuis de nombreuses années. Déjà en 2018, la France s’est dotée d’une stratégie ambitieuse à travers la loi Ma Santé 2022, visant à rassembler les soignants en ville et à l’hôpital autour de projets de santé plus adaptés à l’ensemble du territoire. La pandémie a considérablement accéléré l’adoption des soins à distance. Malgré un marché déjà bien structuré, le personnel de santé et la patientèle restent toujours en attente d’outils pour faciliter les tâches, et surtout la prise en charge ainsi que le suivi des patients. 2022 sera-t-elle l’année de l’e-santé ?
Faciliter la prise en charge et le suivi à distance des patients : le leitmotiv
Ces dernières années, les objets connectés dédiés au domaine médical n’ont cessé de se développer. Selon un rapport réalisé en juin dernier par l’Institut Montaigne, associé au cabinet McKinsey, le marché annuel potentiel de l’e-santé en France se chiffrerait à 22 milliards d’euros.
Ces outils de santé connectés, grâce à l’IoT, permettent de suivre le patient à chaque étape de son traitement, et ce, même à distance. Depuis la crise sanitaire, la téléconsultation s’est popularisée, mais il ne s’agit pas du seul atout de la santé connectée. Les soins quotidiens sont aussi facilités grâce à la télé observance, permettant de relever les constantes précises d’un patient à l’aide d’un simple boîtier (par exemple, pour suivre des patients atteints d’apnées du sommeil ou de diabète).
L'IoT optimise également le suivi des personnes à pathologie chronique ou plus vulnérables grâce à la téléassistance. Les personnes âgées qui vivent seules notamment, peuvent émettre un appel d’urgence en cas de chute ou de malaise grâce à une simple pression sur un bracelet ou médaillon connectés à une assistance 24/7. Les médecins aussi, dans le cadre de la télé expertise, ont la possibilité de solliciter à distance un ou des confrères spécialisés pour compléter un examen médical.
L’objectif ? Lutter contre le désert médical et faciliter l’accès aux soins pour tous. En limitant leurs déplacements les soignants ont plus de temps pour leurs patients, écourtant ainsi les délais d’attente. Le suivi et le contrôle de ces patients gagnent en précision et permettent même d’anticiper les situations à risque et d’intervenir au plus vite.
La vigilance française renforce l’intérêt des patients et soignants pour les nouvelles technologies.
La réglementation encadrant les données de santé issues des objets connectés est très stricte. Depuis 2017 en Europe, tous les objets connectés e-santé doivent obtenir une licence spécifique et les constructeurs sont audités chaque année. En France, depuis 2021, les mandataires, les importateurs et les distributeurs sont également soumis à des contrôles réguliers. L’ensemble des dispositifs médicaux technologiques doivent être certifiés CE, selon les nouveaux règlements 2017/745 européens.
Du côté des patients et également des soignants, la technologie a désormais fait ses preuves et rassure. Le corps médical y voit l’opportunité d’être plus efficace et d’améliorer ses conditions de travail. La nouvelle génération de soignants, qui a grandi avec les nouvelles technologies, réclame une assistance technologique pour réaliser certaines tâches quotidiennes et fluidifier les process.
Mais, en parallèle, des réglementations complexifient le paysage de la santé connectée. Certaines lois, comme la norme HQE, freinent largement les débits cellulaires sur site hospitalier, rendant extrêmement difficiles la connectivité à l’intérieur des bâtiments et donc l’usage des objets connectés. Heureusement, de nouvelles technologies IoT cellulaires dédiées à l’IoT (LTEM, NB-IoT) peuvent répondre à ces contraintes.
Les hôpitaux et maisons de santé en ordre de marche
Certains hôpitaux, comme le CHU de Caen ou de Maubeuge ont déjà commencé à intégrer des capteurs e-santé au sein de leurs structures, et constatent les bénéfices de cette transition digitale.
L’objectif à long terme est aussi d’équiper les maisons de santé, passerelles indispensables entre le patient et l’hôpital. Ces centres régionaux où médecins, auxiliaires médicaux et pharmaciens se regroupent, peuvent traiter 80% des soins et permettent de désengorger les hôpitaux.
Un patient suivi à domicile grâce à la télé observance peut se rendre rapidement en Maison de Santé pour effectuer une consultation à un rythme adapté à son évolution.
Les soignants quant à eux pourraient bénéficier du soutien d’assistants vocaux qui pourraient leur rappeler les informations relatives à un patient en temps réel et faciliter la rédaction des rapports. Un meilleur suivi, avec des analyses optimisées… La digitalisation au service du patient et du corps médical promet de nettes améliorations pour le secteur de la santé sur les prochaines années. La croissance du secteur des technologies au service de la santé s’est largement accélérée avec la crise sanitaire et la France semble enfin se doter d’une législation plus adaptée. La e-santé pourrait apporter une partie des réponses nécessaires à la modernisation et à la transformation du système de santé.
Toulouse devient cette semaine la capitale européenne des transports intelligents en accueillant le sommet européen ITS. Organisé par Ertico (European Road Transport Telematics Implementation Coordination), un partenariat public-privé de plus de 120 entreprises et organisations représentant des prestataires de services, des fournisseurs, l’industrie du trafic et des transports, des instituts de recherche et des universités, des opérateurs de réseaux mobiles ou encore des constructeurs automobiles, ce colloque va réunir quelque 5 000 spécialistes au sein du MEETT, le nouveau parc des expositions et centre de conventions de Toulouse Métropole.
Un espace dédié aux start-up des transports
À l’heure où la crise énergétique est là et où le secteur des transports doit s’adapter à la transition écologique, ce sommet tombe à pic pour imager nos futurs modes de déplacements, connectés et efficients. « Ce congrès illustrera l’ambition européenne du Pacte Vert et constitue une formidable opportunité commerciale pour nos acteurs locaux, nationaux et internationaux », explique Dominique Faure, première vice-présidente de Toulouse Métropole. « Le congrès, l’exposition, les visites techniques et les démonstrations sont une formidable opportunité pour Toulouse Métropole, le territoire et la Région Occitanie, ainsi que pour l’ensemble des acteurs impliqués et visiteurs de voir ce qui se cache réellement derrière la mobilité de demain », se félicite Joost Vantomme, PDG d’Ertico.
Outre les conférences, les nombreux stands d’exposition et les espaces d’échanges, on peut aussi découvrir concrètement des solutions. Ainsi, on pourra découvrir une prestation relative à un système de localisation haute précision grâce à l’intelligence artificielle ou tester une navette autonome. En coordination avec ITS, cet espace sera géré par l’équipe de Mobility Solutions Show – M2S dont La Dépêche est partenaire (stand D17). Le congrès va proposer également un espace d’exposition appelé le Start-up Hub ainsi qu’un programme dédié organisé par l’Initiative Start-up d’Ertico.
Enfin, le grand public ne sera pas oublié : une journée lui est dédiée mercredi 1er juin (gratuite sur inscription).
Lorsque l’on visite la salle des cartes du musée du Vatican ou celle du Palazzo Vecchio à Florence, on est toujours surpris par l’extrême précision des tracés à une époque où les grands explorateurs ne disposaient pas du secours de l’informatique. Quelques siècles plus tard, cette connaissance de notre Terre a bondi grâce à l’informatique et est aujourd’hui accessible à tous grâce notamment à Google qui a facilité l’exploration de la planète avec Google Earth, Maps et Street View. Ce dernier service vient déjà de fêter ses 15 ans d’existence.
220 milliards d’images
Depuis 2007 et les premières photographies à 360° des rues de San Francisco, New York, Las Vegas, Miami et Denver mise en ligne par le célèbre moteur de recherche, « les voitures Street View équipées de caméras ont capturé plus de 220 milliards d’images et parcouru plus de 16 millions de kilomètres, ce qui revient à faire plus de 400 fois le tour du monde » a rappelé Google cette semaine. Afin de célébrer le quinzième anniversaire de cette fonctionnalité aujourd’hui incontournable pour s’orienter ou tout simplement voyager depuis chez soi, Google a mis en avant 15 collections Street View étonnantes. On peut ainsi visiter les 154 étages du Burj Khalifa aux Émirats arabes unis, la Tour Eiffel ou l’intérieur et de l’extérieur du Taj Mahal en Inde. Les Invalides à Paris viennent juste d’être ainsi numérisées.
Un dromadaire dans le désert de Liwa. Photo Google
« Street View n’est pas qu’un outil d’exploration visuelle. C’est aussi un élément essentiel de nos activités de cartographie, qui permet de fournir les informations les plus fiables possible sur le monde qui nous entoure, tout en posant les fondations de la création d’une carte plus immersive et intuitive », explique Google qui n’entend pas se reposer sur ses lauriers et a dévoilé une nouvelle caméra qui ouvre la voie à de futures images. « En plus de nos voitures et de nos Trekkers, nous testons une nouvelle caméra en vue de son lancement l’année prochaine, afin de collecter des images de haute qualité dans de nouveaux lieux. Toute la charge, la résolution et la puissance de calcul, jusqu’alors intégrées à une voiture, seront désormais disponibles dans une seule caméra ultra-transportable, pas plus imposante qu’un gros chat. Nous pourrons l’emporter avec nous dans des zones isolées, sur des îles, des montagnes, ou simplement pour faire un tour du quartier » se félicite Google.
Pesant 7 kg, cette caméra peut se voir adjoindre des modules complémentaires comme un lidar (un scanner laser) et est installable sur n’importe quel véhicule ou bien portée à la main pour photographier des intérieurs.
Grâce désormais à son ancienneté, Google propose aussi de remonter le temps et de voir sa rue évoluer au fil des ans, la mise à jour des photos s’effectuant par des passages des caméras de Google tous les 3-4 ans ou plus pour les grandes villes.
Prochaine étape, couvrir encore plus de territoires et proposer une innovation : la vue immersive. En fusionnant des milliards d’images Street View et aériennes, Google va créer un modèle numérique 3D très complet. Rendez-vous bientôt pour Los Angeles, Londres, New York, San Francisco et Tokyo.
Tandis que l’on assiste à l’avènement des métavers et des NFT, les frontières entre le monde digital et le monde matériel se brouillent davantage avec le lancement début mai d’une édition limitée de Coca-Cola au « goût de pixels » : le Coca-Cola Byte. Selon la marque, le produit « invite à explorer le goût que pourraient avoir les pixels avec une expérience Coca d’une nouveauté rafraichissante nouveauté tout en étant délicieusement familière ». Ainsi, pour la somme de 14,77 dollars, il est possible de s’offrir deux canettes de la boisson et un sticker « commémoratif » (terme employé par la marque sur son site).
Quel est le goût d’un pixel ?
Selon le site de la marque, le soda propose une expérience gustative offrant « une mise en bouche lumineuse évoquant le démarrage d’un jeu vidéo suivie d’un goût rafraîchissant qui en fait un parfait compagnon de jeu ». Le ton est donné : la boisson s’adresse aux adeptes des jeux vidéo et adopte les codes et le vocabulaire du « gaming ».
L’achat du coffret donne accès à un mini-jeu en réalité augmentée développé pour l’occasion et le lancement s’accompagne d’un espace aux couleurs du produit crée dans le jeu Fortnite. De façon plus empirique, le Coca-Cola Byte propose un goût proche de son plus classique cousin, le Coca Zero, tout en étant plus pétillant.
Ce lancement de produit, aussi intrigant soit-il, relève avant tout d’une démarche marketing. Coca-Cola s’approprie le langage et les codes du digital pour s’adresser à une cible (vraisemblablement celle des gamers) et s’en attirer les faveurs. Il n’est évidemment pas réellement question de connaître soudain le goût des pixels mais de découvrir l’interprétation que la marque en fait dans le cadre d’une opération marketing. Pourtant, le simple fait qu’une marque envisage « le goût des pixels » comme une proposition attrayante et compréhensible ne peut que nous interroger sur les frontières entre le monde digital et le monde matériel.
Hybridation du monde digital et du monde matériel
En donnant la possibilité de « goûter des pixels », le Coca-Cola Byte illustre une hybridation dans les codes du digital et de la matérialité. On observe en effet un nombre croissant d’incursions d’un monde dans l’autre et la frontière entre les deux semble plus poreuse que jamais.
Avec le développement de la présence d’Internet dans nos vie quotidiennes s’est mise en place une digitalisation croissante d’éléments jusqu’alors matériels. C’est notamment ce que l’on nomme la consommation virtuelle digitale (Digital Virtual Consumption), qui nous a amenés à remplacer peu à peu nos albums de photos de famille par des dossiers sur nos ordinateurs, nos collections de DVDs par des fichiers de films, puis des abonnements à des plates-formes de streaming et même nos relevés bancaires par des e-mails.
Jusque récemment, ces objets digitaux étaient considérés comme ayant fondamentalement moins de valeur que des objets matériels. Le développement rapide et massif du phénomène des jetons non fongibles (non-fungible tokens, ou NFT) vient profondément remettre en question cette hypothèse d’une valeur toujours inférieure des objets digitaux. En garantissant à l’objet digital une unicité et en lui accordant le statut d’œuvre d’art, les NFT donnent à des objets digitaux une valeur (symbolique et monétaire) bien supérieure à certaines œuvres d’art bien matérielles.
Mais la digitalisation ne passe pas seulement par la transformation d’objets matériels en objets digitaux. On observe également l’intervention du digital au sein même du monde matériel, par le biais de la réalité augmentée notamment, qui en transforme la perception. On se souvient par exemple du phénomène de Pokémon Go qui a pris une ampleur inattendue pendant l’été 2016 (et qui, malgré un net ralentissement, bénéficie encore aujourd’hui d’une large communauté d’adeptes) en amenant des millions de personnes, dans le monde entier, à guetter l’apparition de créatures virtuelles dans des lieux bien réels, à travers l’objectif révélateur de leur smartphone. Ainsi, avec la réalité augmentée, des éléments virtuels apparaissent sous nos yeux, dans le monde matériel. Dans un esprit similaire, il est aujourd’hui possible de se rendre dans une boutique physique pour réaliser des achats virtuels.
L’entreprise Meta a ainsi ouvert un Meta Store début mai en Californie pour permettre aux utilisateurs du métavers Horizon World lancé par la maison mère de Facebook d’acheter des accessoires virtuels pour leurs avatars.
Goûter à l’immatériel
Le Coca-Cola Byte, lui, va à l’encontre de ces deux types d’hybridation du monde digital et du monde matériel. Jusque-là, il a été question de digitaliser le monde matériel ou d’importer le digital en son sein. Avec ce lancement de produit, la marque propose une tout autre démarche : celle de rendre le digital sensible, de lui donner une dimension sensorielle.
En offrant aux consommateurs et consommatrices de goûter à l’immatériel, Coca-Cola propose une expérience de brouillage sensoriel et de matérialisation du digital. Certes, il s’agit avant tout d’une démarche commerciale mais il est aussi possible d’y voir les éléments d’un questionnement plus profond. Digital, virtuel, immatériel, numérique versus physique, réel, matériel, analogue… Est-il encore pertinent de penser ces deux mondes comme étant opposés ? Il convient peut-être aujourd’hui de repenser ces concepts pour mieux en saisir la porosité et les nombreuses hybridations.
Les études diverses sur les habitudes de sauvegarde des entreprises et leurs collaborateurs sont sans équivoque : très majoritairement, elles ne s’attardent vraiment sur ces questions de sauvegarde ou de récupération qu’en cas d’incidents. Pourtant la sauvegarde est l’élément majeur des dispositifs de cyber-résilience, à savoir la capacité à rester opérationnel, même face aux cyberattaques et à la perte de données.
La sauvegarde n’est pas suffisamment considérée
Dans les faits, force est de constater que la sauvegarde n’est pas envisagée dans son entièreté par les entreprises qui n’ont pas eu à subir d’accidents et il est fréquent qu’elles ne sauvegardent pas les éléments les plus pertinents. A titre d’exemples une entreprise peut ne sauvegarder qu’un ou deux serveurs, ou un élément qu’elle a identifié comme critique quelques années auparavant. Certaines ne tiennent pas compte de l’évolution de leur environnement à la suite de l’embauche de nouveaux salariés par exemple ou de l’adoption de nouveaux services. Il n’est pas rare qu’elles n’aient pas revu leur plan de cyber-résilience et le volet protection/sauvegarde des données même à la suite de changements en interne.
De même, bon nombre d’entreprises n’ont pas encore suffisamment pris en compte les changements d’usages comme l’augmentation de l’utilisation des ordinateurs portables accentuée par la pandémie et le travail hybride. Il y a cinq ans, les salariés travaillaient majoritairement sur des ordinateurs de bureau et les entreprises disposaient d’un serveur unique. Maintenant un grand nombre de données d’entreprise, parfois critiques se trouvent exclusivement sur les terminaux utilisés par les collaborateurs et la stratégie de sauvegarde doit s’adapter pour garantir la continuité surtout en cas d’incidents.
Il y a aussi les cas où les entreprises mettent en balance leurs ressources et leurs besoins et établissent leur stratégie de sauvegarde autour d’outils comme la suite Microsoft® 365 par exemple, mais oublient que cet outil maintient les données sous leur responsabilité. En cas de suppression accidentelle ou intentionnelle de dossiers, il n’y a pas de récupération garantie si l’entreprise n’a pas prévu une solution de sauvegarde tiers.
La stratégie de protection des données comprend les outils et les processus
Le processus seul ne suffit pas à résoudre les problèmes de sauvegarde et protection des données, il faut également disposer d’outils. On ne peut jamais tout à fait se fier aux processus, vous aurez toujours un collaborateur qui n’aura pas saisi toutes les informations, vu les mémos. Par ailleurs, il y a aujourd’hui un nombre significatif de salariés qui considèrent que la cybersécurité et la protection des données ne concernent que les services informatiques. De même, trop peu d’entreprises jugent la cyber-résilience comme une responsabilité partagée par tous. C’est pourquoi les programmes de formation sont essentiels afin de sensibiliser et éduquer les collaborateurs aux meilleures pratiques, ils sont des éléments importants des stratégies de cyber-résilience.
Les étapes nécessaires d’une stratégie de sauvegarde
Il y a quelques étapes imparables pour verrouiller une stratégie de sauvegarde. Tout d’abord il faut savoir avec précision où sont stockées les données pour les protéger. Sont-elles sur Microsoft 365, google, Dropbox ou localement sur les terminaux ? Ensuite il faut classer les systèmes dans différentes catégories en fonction des besoins comme le type de sauvegarde, la vitesse de restauration et le fait que les données soient stockées localement, dans le cloud, ou les deux. Les besoins de déploiement varient en fonction des systèmes. En cas de serveurs de niveau 1 critique, l’entreprise aura besoin d’un objectif de point de récupération (RPO) et d’un objectif de temps de récupération (RTO) très rapides. Pour d’autres systèmes une panne de quatre heures peut être gênante mais sans gravité. D’autres peuvent avoir un système différent, comme le stockage à long terme, pour lesquels il n’y aura pas de dommage si l’on peut récupérer les données en une ou deux semaines.
Il faut toujours réexaminer les plans de sauvegarde. L’infrastructure informatique des entreprises évolue si rapidement que la stratégie doit être revue au moins deux fois par an, voire tous les trimestres. Il convient de toujours garder à l’esprit certaines questions : ai-je ajouté une nouvelle application ou de nouvelles données ? Les données de mes nouveaux collaborateurs sont-elles sauvegardées ? Mes sauvegardes sont-elles testées ? Ai-je un nouveau serveur ou le serveur existant est-il passé d’une catégorie 2 à 1 ?
Alors que de plus en plus d’actifs travaillent à distance et que les entreprises s’appuient davantage sur les applications de collaboration et de partage de fichiers, il est essentiel de réexaminer régulièrement les plans de sauvegarde et de reprise après sinistre, pour s’assurer qu’il n’y a pas de lacune dans la protection des données. Il est également important d’investir dans des outils capables de sauvegarder la suite Microsoft 365, et de garantir que les données enregistrées sur les terminaux soient toujours récupérables, quel que soit l’endroit où se trouvent les terminaux. En outre, il faut donner aux équipes les moyens de devenir plus cyber-résilients et mettre en place une formation et une sensibilisation à la cybersécurité.
Les attaques par hameçonnage vocal (vishing ou voice phishing) ont augmenté de près de 550 % au cours des douze derniers mois (T1 2022 à T1 2021), selon le dernier rapport trimestriel sur les tendances en matière de menaces d'Agari et de PhishLabs, deux sociétés intégrées au portefeuille cybersécurité de HelpSystems.
Au cours du premier trimestre 2022, Agari et PhishLabs ont détecté et contré des centaines de milliers d'attaques de phishing en provenance des réseaux sociaux, messageries électroniques et du dark web ciblant un large éventail d'entreprises et de marques. Ce rapport analyse les principales tendances du paysage des menaces actuel.
Les attaques par vishing dépassent la compromission des e-mails
Depuis le troisième trimestre 2021, les attaques par vishing ont dépassé la compromission des e-mails professionnels, se positionnant comme deuxième source de menaces pesant sur les systèmes de messagerie électronique. À la fin de l'année, ces dernières représentaient plus d'une menace sur quatre, et cette tendance s'est poursuivie au premier trimestre 2022.
« Les campagnes de vishing hybride continuent de générer des chiffres stupéfiants, puisqu'elles constituent 26,1 % du volume total des attaques enregistrées jusqu'à présent en 2022 », indique John LaCour, stratège principal chez HelpSystems. « On assiste à une multiplication des acteurs de la menace qui délaissent les campagnes de phishing vocal standards pour lancer des attaques par e-mail malveillant en plusieurs étapes. Au cours de ces attaques, les hackers se servent d'un numéro de rappel inséré dans le corps de l'e-mail comme appât, puis s'appuient sur l'ingénierie sociale et l'usurpation d'identité pour inciter la victime à appeler et à interagir avec un faux représentant. »
Autres enseignements de ce rapport :
Les attaques par usurpation d'identité sur les réseaux sociaux sont en hausse. Depuis le deuxième trimestre 2021, le volume des usurpations d'identité ciblant les marques a bondi de 339 % et celui des usurpations d'identité de dirigeants de 273 %. D'après les résultats, les marques constituent des cibles faciles pour les cyber criminels, surtout lorsqu'elles sont associées à des opérations de contrefaçon de produits vendus au détail. Cependant, pour certaines attaques ciblées, des comptes sociaux de dirigeants sont utilisés pour renforcer le réalisme.
Les escroqueries par e-mail dont l'objectif est le vol d'identifiants restent le type de menaces par messagerie électronique le plus courant signalé par les collaborateurs, à hauteur de près de 59 % de tous les typologies de menaces rencontrées. Les vols d'identités ont augmenté de 6,9 % en volume par rapport au quatrième trimestre 2021.
Le paysage des malware est en constante évolution. Qbot a été une fois de plus le malware le plus usité par les acteurs de la menace pour servir leurs attaques par ransomware, mais Emotet a refait surface au premier trimestre prenant la première place du podium.
Alors que près de la moitié des sites d'hameçonnage s'appuient sur un outil ou un service gratuit, le premier trimestre 2022 a été le premier de cinq trimestres consécutifs où les services payants ou compromis (52 %) ont dépassé les solutions gratuites pour les mises en scène des sites de phishing.
« Comme la diversité des canaux numériques utilisés par les entreprises pour conduire leurs activités et communiquer avec les consommateurs se développe, les hackers disposent de multiples vecteurs pour conduire leurs exactions », ajoute John LaCour. « La plupart des attaques ne démarrent pas de zéro ; elles reposent sur la refonte de tactiques traditionnelles et l'intégration de multiples plateformes. Pour continuer à se protéger, les entreprises ne doivent plus uniquement se concentrer sur une protection périmétrique mais augmenter leur visibilité sur différents canaux externes, afin de recueillir des renseignements et de surveiller les menaces de manière proactive. En outre, les équipes de sécurité doivent investir dans des partenariats qui garantiront la prévention rapide et complète des attaques avant qu'elles n'entraînent des préjudices financiers et des atteintes à la réputation. »
Selon un sondage représentatif commandé par le fournisseur de messagerie GMX, de nombreux internautes français sont préoccupés (31%), voire très inquiets (9%), d'être victimes d'un vol d'identité. La majorité craint que des inconnus puissent faire des achats (52%) avec leur argent. Dans le cas d'une usurpation d'identité, les criminels accèdent aux comptes en ligne et agissent au nom de leurs victimes. De nombreuses personnes interrogées craignent que des inconnus signent des contrats en leur nom (37 %), que des escrocs utilisent l'identité volée pour ouvrir de nouveaux comptes (36 %) et que des informations les plus privées tombent entre des mains étrangères ou soient rendues publiques (28 %).
Besoin de rattrapage en matière de sécurité des mots de passe
Il est urgent de rattraper le retard en matière d'utilisation de mots de passe sûrs selon GMX : 34 % des utilisateurs d'Internet en France utilisent dans leurs mots de passe des informations personnelles telles que les dates de naissance de la famille, des partenaires ou des amis (13%), les dates importantes comme les anniversaires (11 %) ou le nom de l'animal domestique (8%). Les noms des enfants, du partenaire ou de la partenaire (7 %) sont également une source de mot de passe populaire. Beaucoup de ces informations sont souvent disponibles sur les plateformes de médias sociaux, de sorte que les mots de passe peuvent être facilement devinés.
« L'usurpation d'identité est un véritable cauchemar pour de nombreux internautes. Il convient d'accorder une attention particulière à son compte de messagerie, car il permet de se connecter à la plupart des services et de réinitialiser les mots de passe. Outre un mot de passe fort et unique pour chaque service, il faut également activer l'authentification à deux facteurs », explique Jan Oetjen, directeur général de GMX.
Après l'activation d'une authentification à deux facteurs (2FA), le mot de passe ne suffit plus pour se connecter au compte Internet. Lors de la connexion, il faut en outre indiquer un autre facteur d'authentification auquel seul le propriétaire du compte peut avoir accès. La plupart du temps, ce deuxième facteur est un code numérique unique, reçu par exemple par SMS ou généré dans une application pour smartphone.
Plusieurs études du discours médiatique ont mis en lumière, par des analyses quantitatives et qualitatives, des soutiens à peine voilés de certains médias envers certains courants politiques. Et si l’on inversait la question ? Bien qu’on ait tendance à considérer, par exemple, qu’un lecteur régulier du Figaro s’oriente politiquement à droite, peut-on établir des corrélations à grande échelle entre choix de sources d’information et orientation politique ?
Des études basées sur des enquêtes d’opinion ont montré notamment la part grandissante des réseaux sociaux dans la diffusion de l’information et le rôle qu’ils jouent dans la formation de l’opinion publique depuis une décennie, à l’image des évolutions observées lors de deux dernières élections aux États-Unis (voir ici et ici).
Les médias traditionnels ont intégré cette donnée et utilisent les réseaux sociaux en se faisant l’écho des discussions qui y ont lieu mais aussi en y diffusant des informations via des comptes dédiés.
Nous pouvons alors utiliser les données massives que fournissent ces plates-formes pour obtenir, de façon automatique, une cartographie des pratiques d’information en fonction de l’orientation politique des usagers. Nous essayons ainsi de répondre à la question « Qui lit/écoute/regarde quoi ? » en fonction de son orientation politique.
Dans ce but nous avons observé, depuis septembre 2021, presque 22 millions d’utilisateurs de Twitter qui suivaient (follow), au moins, un candidat à l’élection présidentielle de 2022 en France, et/ou le compte Twitter de 20 médias parmi les plus importants du pays, tous formats confondus (TV, radio, Internet, presse traditionnelle). Sur ce total de 22 millions, seulement 11 millions suivaient au moins l’un des candidats (le reste ne suivant aucun candidat, et uniquement un ou ou plusieurs des médias retenus).
Le choix de Twitter est motivé, d’une part, par le fait que la plate-forme facilite l’accès aux données pour la recherche. D’autre part, la nature des billets postés (tweets) – nombre de caractères limités, utilisation des mots clés (hashtags), rapidité de réaction des utilisateurs – permet de tirer des informations sur les usagers sans avoir recours à des techniques plus compliquées d’analyse textuelle.
Après avoir filtré les utilisateurs « actifs », c’est-à-dire, ceux qui publient des tweets sur la plate-forme ou qui relayent (retweet) ceux des autres, nous avons détectés ceux qui déclarent être localisés en France.
Nous avons ensuite classé les usagers en fonction du candidat soutenu, en considérant comme indicateur de « soutien » le fait de produire un retweet direct (sans ajouter de commentaire) des tweets du candidat en question.
Nous avons aussi créé une catégorie « partisan ». Nous y avons rangé les usagers dont plus de 75 % des retweets d’aspirants à la magistrature suprême correspondent à un même candidat. Par exemple, une personne dont 75 % des retweets de candidats sont des messages postés par Valérie Pécresse est considérée comme partisane de cette dernière.
De la même façon, nous avons identifié les usagers ayant un « média préférentiel », c’est-à-dire un média qui concentre plus de 75 % de leurs retweets de différents médias.
Pour l’analyse du comportement des partisans, nous avons choisi de ne retenir que les comptes qui déclarent être situés en France. Les utilisateurs ont la possibilité de remplir eux-mêmes, sur leur profil, un champ indiquant où ils se trouvent géographiquement. Cette déclaration étant facultative sur Twitter, il n’y a qu’une minorité d’utilisateurs qui déclarent une localisation. Suivant une méthode déjà testée dans une étude similaire, nous cherchons sur le profil des utilisateurs, une mention (pays, région, ville) permettant de les situer en France. Ce critère strict réduit notre base de données mais nous permet de diminuer l’effet des biais potentiellement introduits par des comptes étrangers et/ou automatisés.
Ainsi, au 20 mars 2022, à moins de trois semaines du premier tour, 3,7 % des 11 millions de comptes étudiés – soit environ 400 000 comptes – se déclarent en France.
La distribution des données pour chaque candidat
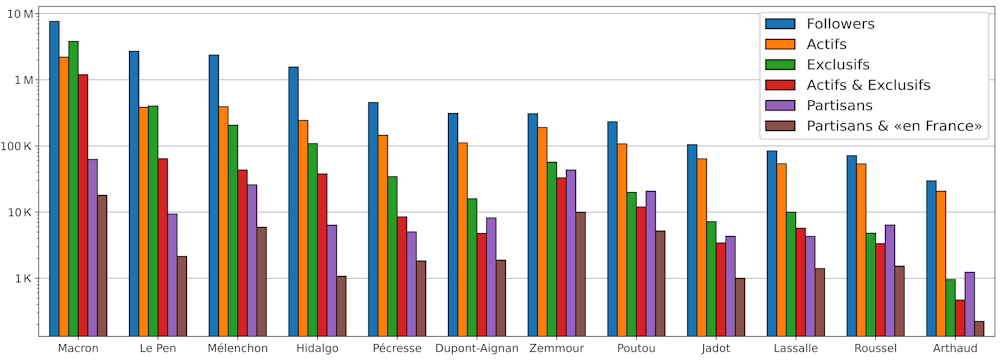
La Figure 1, montre le total de followers des différents candidats et leur classification, au 20 mars 2022. On peut voir comment se distribuent les presque 11 millions de followers de candidats ainsi que la population correspondant aux différents filtres appliqués.
Figure 1.Followers : total des comptes qui suivent le candidat sur Twitter. Actifs : followers qui suivent le candidat et publient des posts (tweets) ou transfèrent (retweet) ceux des autres utilisateurs. Exclusifs : comptes Twitter qui suivent exclusivement le candidat. Actifs & exclusifs : comptes qui suivent exclusivement le candidat et qui sont actifs (tweet et/ou retweet). Partisans : comptes Twitter dont plus de 75 % des retweets correspondent au candidat. Partisans & « en France » : partisans localisés en France. Noter que l’échelle verticale est logarithmique.Rémi Perrier/LPTM, Fourni par l'auteur
On observe que pour le candidat Macron, sur un total de 7,6 millions de followers, il y a environ 2,6 millions de followers exclusifs (qui suivent Emmanuel Macron mais aucun autre candidat, ni média de la liste) et qui ne retweetent jamais.
Ceci pourrait s’expliquer, puisqu’il s’agit du président sortant. Il est naturel que des utilisateurs soucieux de suivre l’actualité présidentielle s’abonnent au compte du locataire de l’Élysée, sans pour autant s’en sentir politiquement proches.
Rémi Perrier/LPTM
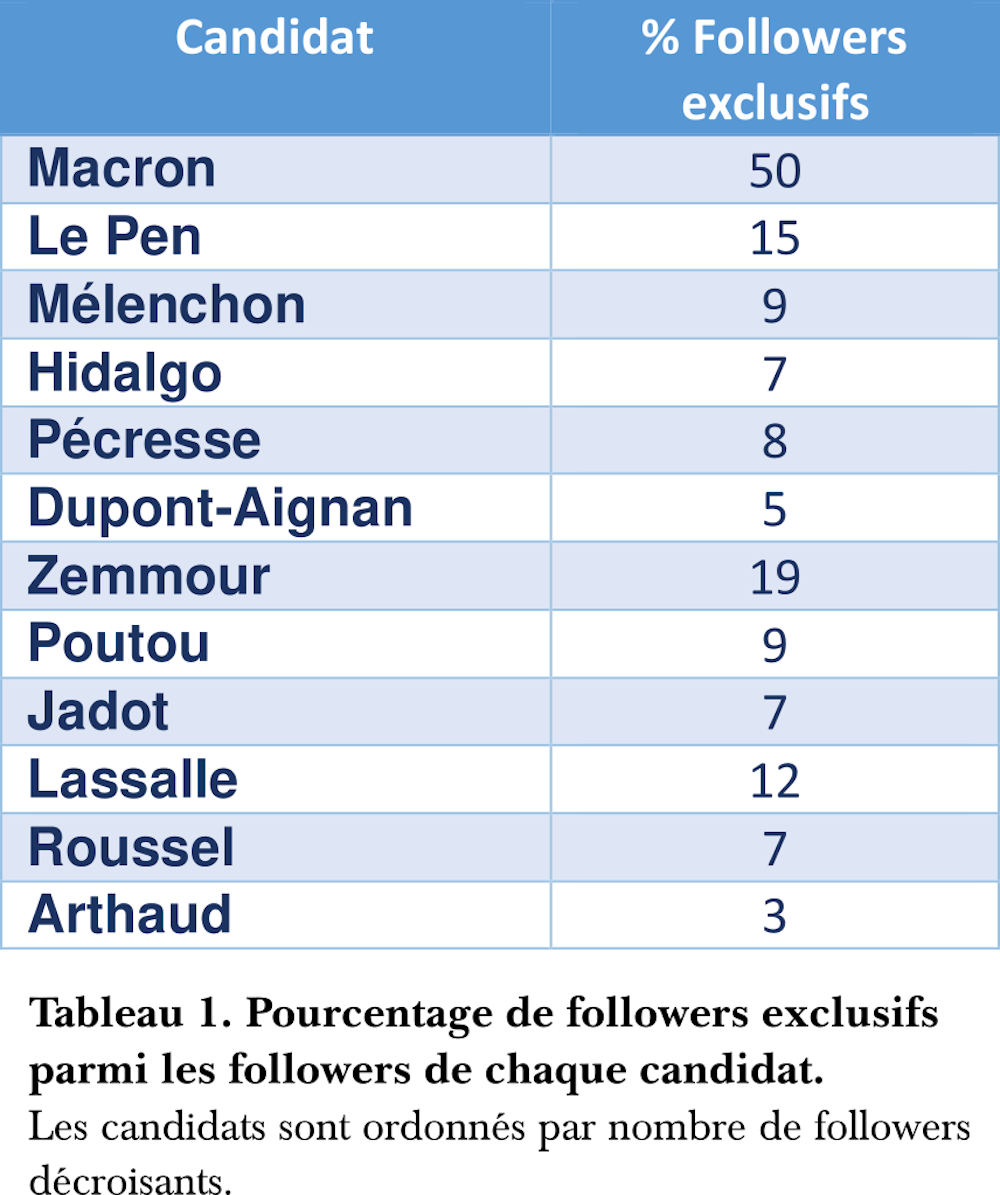
Le Tableau 1 (ci-contre) donne le pourcentage des followers parmi les 11 millions de comptes analysés, qui ont décidé de suivre exclusivement un seul candidat (ni autre candidat, ni aucun des médias considérés). Ces comptes ne sont pas nécessairement des partisans (ces derniers étant définis par des retweets majoritaires du candidat), en revanche ils manifestent une attention particulière pour le candidat.
Ainsi, mis à part le cas déjà évoqué du président candidat, ce tableau met en évidence des pourcentages élévés d’attention exclusive envers Éric Zemmour, suivi par Marine Le Pen et Jean Lasalle. Tous les autres candidats ayant moins de 10 % de followers exclusifs.
Quels partisans suivent quels médias ?
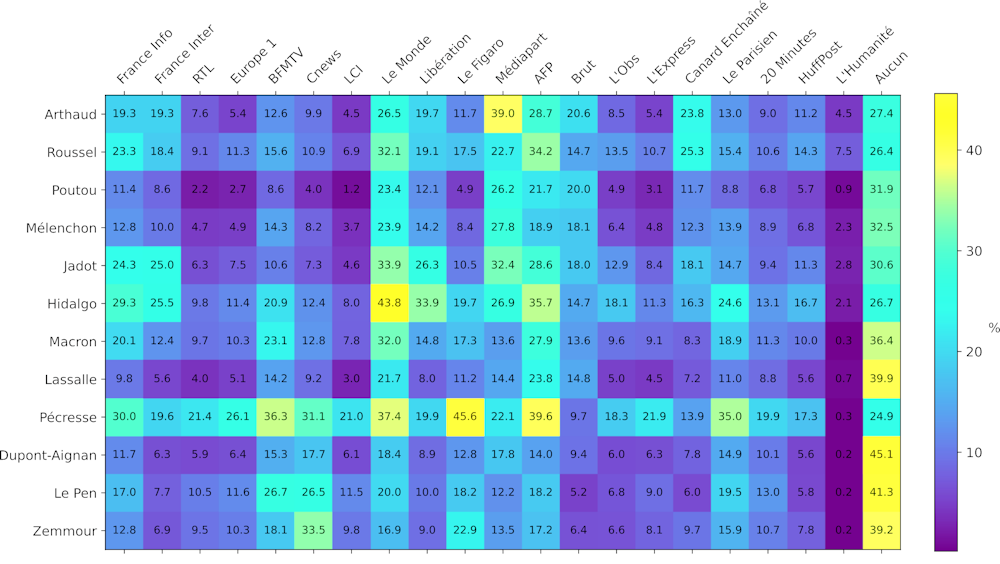
La Figure 2 (ci-dessous) montre la proportion des partisans des différents candidats qui ont décidé de suivre sur Twitter les informations diffusées par les différents médias. Il faut, par exemple, la lire ainsi : « 39 % des partisans de Nathalie Arthaud sont abonnés au compte Twitter de Médiapart ».
On voit que l’attention des partisans est majoritairement captée par des quotidiens nationaux de presse écrite (y compris en ligne, comme @Médiapart), ainsi que par l’Agence France-Presse.
Figure 2. Pourcentages des partisans localisés en France qui suivent les différents médias. Chaque case représente le pourcentage des partisans du candidat, indiqué sur la ligne, qui suivent le média indiqué sur la colonne. La colonne tout à droite indique le pourcentage de partisans qui ne suivent aucun média, pour chaque candidat. Pour améliorer la lisibilité, les candidats ont été classés de l’extrême gauche en haut à l’extrême droite en bas, et un code couleur est attribué aux pourcentages qui sont lisibles dans chaque case. L’échelle de couleur est présentée à droite du tableau et indique que plus la couleur vire au jaune, plus le pourcentage est élevé. Noter que le total par ligne ne fait pas 100 % car un même partisan peut suivre plusieurs médias.Rémi Perrier/LPTM, Fourni par l'auteur
Sans surprise, on observe que le compte du journal Le Monde (@lemondefr) est très suivi, notamment par des partisans des candidats Anne Hidalgo, Yannnick Jadot et Valérie Pécresse, tandis que celui du Figaro (@Le_Figaro) est nettement préféré par les partisans de Valérie Pécresse.
On remarque que les partisans de Valérie Pécresse suivent le compte de BFM (@BFMTV) et celui du Parisien (@le_Parisien) beaucoup plus que les autres.
Finalement, la couleur nettement plus sombre de la partie inférieure du tableau fait ressortir le fait qu’en général, les partisans des candidats d’extrême droite suivent beaucoup moins les comptes des médias que les autres.
On observe surtout une prédominance des comptes des chaînes d’information en continu (@BFMTV, @CNews) chez ces partisans, préférées aux quotidiens nationaux.
Quels partisans relayent les messages de quels médias ?
Si l’on s’intéresse à l’adhésion que les partisans des candidats expriment par rapport aux informations diffusées par les comptes des médias, le paysage change radicalement.
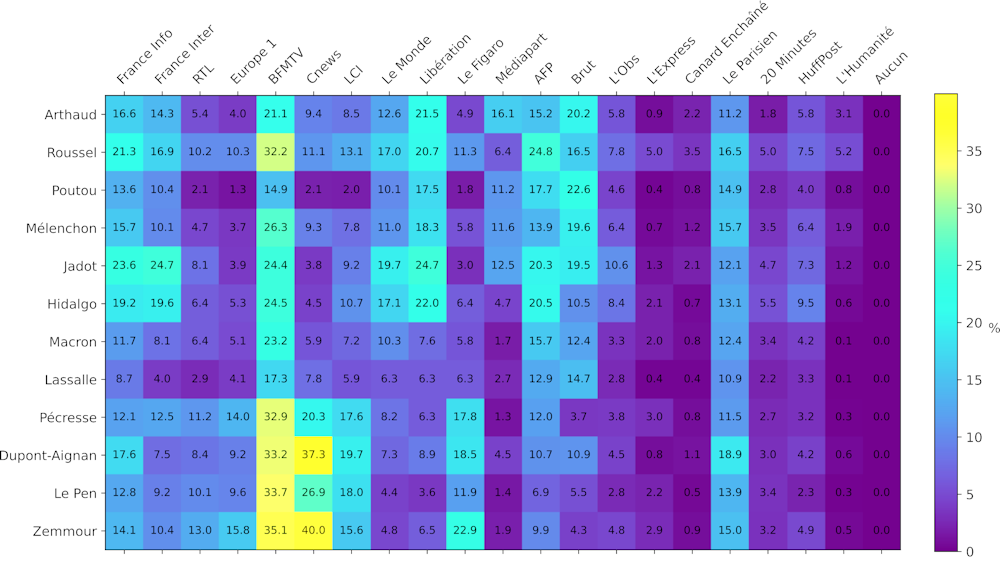
La Figure 3 donne la proportion des partisans des différents candidats qui ont relayé (retweet) les informations publiées sur Twitter par les différents médias. Il faut, par exemple, la lire ainsi : « 32,2 % des partisans de Fabien Roussel ont retweeté au moins une fois un tweet de BFMTV ».
Figure 3. Pourcentages partisans localisés en France qui retweetent les différents médias. Chaque case représente le pourcentage des partisans du candidat, indiqué sur la ligne, qui relayent les tweets du média indiqué sur la colonne. Pour améliorer la lisibilité, les candidats ont été classés de l’extrême gauche en haut à l’extrême droite en bas, et un code couleur est attribué aux pourcentages qui sont lisibles dans chaque case. L’échelle de couleur est présentée à droite du tableau et indique que plus la couleur vire au jaune, plus le pourcentage est élevé. Noter que le total par ligne ne fait pas 100 % car un même partisan peut relayer les tweets de plusieurs médias.Rémi Perrier/LPTM, Fourni par l'auteur
On observe une nette prédominance de retweets des chaînes d’information en continu. Il faut noter que celles-ci ont tendance à publier plus de contenu vidéo que les comptes de la presse traditionnelle, ce qui peut contribuer au résultat observé.
Cependant, il est intéressant de remarquer que, à l’exception des partisans de Fabien Roussel, cette tendance à relayer les chaînes d’information en continu s’accentue chez les partisans de candidats de droite et d’extrême droite.
On voit aussi que les comptes des radios publiques, @franceinter et @franceinfo, sont nettement plus relayés par les partisans d’Anne Hidalgo et de Yannnick Jadot que par les partisans des autres candidats.
Quels partisans relayent exclusivement les messages de quels médias ?
Les partisans ayant un média préférentiel, en se limitant à relayer les messages de ce dernier, révèlent un fort alignement avec l’orientation éditoriale du média en question.
La Figure 4 (ci-dessous) montre la proportion des partisans du candidat correspondant à chaque ligne ayant relayé majoritairement les tweets des médias indiqués sur les colonnes. Il faut ainsi lire : « 3,3 % des partisans de Yannick Jadot ont France Inter pour média préférentiel ».
En général, le pourcentage de partisans concentrés sur un unique média est faible. Les plus grandes proportions de partisans se concentrant sur peu de médias se trouvent à l’extrême droite du spectre politique.
Ce phénomène évoque les « chambres d’écho » observées sur les réseaux sociaux : les utilisateurs sont confrontés à des opinions similaires ou à des informations issues d’un nombre très restreint de sources, qui encadrent et renforcent un récit commun.
Comme sur la Figure 3, on retrouve la prééminence de @BFM et @CNews et on peut clairement observer l’inversion des préférences entre les partisans de Marine Le Pen et d’Éric Zemmour : les premiers suivent davantage BFM, tandis que le seconds sont davantage amateurs de CNews, en accord avec les études qui ont suivi les nombreuses polémiques concernant un excès d’attention de @CNews pour ce dernier.
Finalement, on note (figures 2 à 4) que les partisans de l’extrême gauche et de l’extrême droite ont un comportement assez différent par rapport aux médias. Tandis que ceux de l’extrême droite concentrent leur attention sur peu de médias, ceux de l’extrême la gauche se distribuent sur un panel bien plus large.
Cette simple analyse statistique de données publiques fournit une cartographie qui permet de mesurer des tendances générales dans le choix fait par les partisans des différents candidats concernant l’accès à l’information et sa diffusion.
Même si les résultats sont limités aux utilisateurs de Twitter, la mesure de leur rapport aux médias traditionnels donne un socle sur lequel baser les discussions concernant le rôle des médias dans la formation de l’opinion en période électorale.
Ce travail a été financé en partie par le projet OpLaDyn (Trans-Atlantic Platform Digging into Data Challenge : 2016-147 ANR OPLADYN TAP-DD2016) et le Labex MME-DII (contrat No. ANR Référence 11-LABEX-0023).
Laura Hernandez, MCF-HDR Physique. Thèmes de recherche: application des notions et méthodes de Physique à l'étude des problèmes presentant des structures et dynamiques complexes, tout domaine disciplinaire confondu., CY Cergy Paris Université et Rémi Perrier, Doctorant en systèmes complexes, CY Cergy Paris Université
Avis d’expert de Frédéric Fourquet, Product Marketing Manager, chez MEGA International
Considérée comme une source d’innovation et de valeur ajoutée, la donnée est un élément dont la valorisation reste difficile dans les entreprises, et ce malgré une prise de conscience et de nombreuses initiatives ces dernières années. Dans les faits, le partage de la donnée dans les organisations ne se décrète pas, il se motive, afin que les métiers jouent le jeu. Et les motivations sont simples : le réglementaire représente une nécessité impérieuse pour tous les acteurs, mais c’est surtout l’innovation qui permet de réaliser les gains de performance et les potentialités de croissance. Le processus demeure toutefois complexe avec des défis majeurs à relever en matière de data gouvernance.
1 – Impliquer les métiers pour les motiver
Données clients, informations industrielles et métiers, données financières, etc. : dans une organisation, les données sont nombreuses et ne cessent d’augmenter avec le digital. Leur point commun : elles sont la propriété d’une fonction métier ou d’une fonction support. Si historiquement certaines données sont partagées entre les fonctions (données clients entre le marketing et le commerce, données produits entre les études et la production, données financières entre le commerce et la DAF, etc.), c’est aujourd’hui la transversalité complète dans l’organisation qui est en mesure de créer de la valeur par l’innovation.
Pour autant, cette transversalité peut-elle se décréter ? Oui en partie, avec des réglementations (et les amendes associées) qui imposent une gestion globale des données dans le cadre d’une obligation de conformité. C’est le cas par exemple du RGPD, pour laquelle l’entreprise doit prouver sa maitrise et sa bonne gestion de l’ensemble des données personnelles traitées au sein de l’organisation.
Mais pour être réellement source d’innovation, cette transversalité s’acquiert : les métiers doivent comprendre en quoi partager leurs données avec les autres acteurs de l’organisation peut leur apporter des bénéfices, et donc les motiver. L’utilisation de l’intelligence artificielle fournit un bon exemple. C’est en mettant en commun toutes les données pour une gouvernance globale que l’ensemble des métiers peuvent en retour bénéficier des innovations disruptives qu’offre l’IA: détection de signaux faibles, compréhension fine des comportements clients, etc. sur la base de données stables, fiables et maitrisées.
Si la proximité de l’équipe data science avec les métiers peut être une motivation supplémentaire, une phase d’évangélisation et d’on-boarding est essentielle. C’est l’un des rôles du CDO (Chief Data Officier) qui est là pour organiser la connaissance, favoriser les échanges, s’assurer de la fiabilité et de la conformité des données. Il est aussi là pour embarquer chaque « propriétaire » de données dans la démarche. Concrètement, pour construire cette culture partagée de la donnée, le CDO devra trouver des sponsors métiers - y compris de niveau CODIR, mettre en place une charte de la démarche de Data Gouvernance, puis organiser la démarche d’information, de communication et d’induction des différents correspondants data.
2 – Réconcilier technicité de la data gouvernance et besoins métiers
La data gouvernance vise à connaître et cataloguer toutes les données d’une organisation, à évaluer et améliorer leur qualité et conformité, pour les mettre à disposition des parties-prenantes qui assurent la bonne marche de l’entreprise. Un concept extrêmement technique donc - les données étant l’apanage du système d’information, alors qu’il s’agit en priorité de répondre à des besoins et des enjeux métiers. Et c’est bien ce besoin, ce cas d’usage concret qui doit demeurer le point de départ de tout projet : par exemple, détecter des futurs clients ayant une appétence pour tel ou tel produit, détecter les risques de départ de clients, etc.
Sur la base d’un cas d’usage défini, les métiers vont sélectionner avec les data scientistes les concepts métiers et les dimensions de données les plus pertinentes. Ce « Data Shopping » se réalise via, tout d’abord, le glossaire métier (concepts et éléments liés) puis via le data catalogue, qui est l’image concrète des données dans les systèmes réels (applications) - et donc les sources de données à réutiliser en fonction de la qualité, de la validité, de la fraîcheur des données, etc. Cette partie technique est évidemment primordiale, elle devient plus facilement accessible pour tous les acteurs via le glossaire métier.
3 – Modéliser le cycle de vie des données
La data n’est pas statique, elle dispose d’une durée de vie. C’est pourquoi, une simple cartographie ne suffit pas : la data gouvernance nécessite de modéliser l’ensemble du cycle de vie des données : création, utilisation, réutilisation, obsolescence, destruction (RGPD). Objectif : lier la modélisation des processus métiers et la data gouvernance, afin de gagner en temps et compréhension des enjeux métiers.
Dans ce contexte, pour accélérer la data gouvernance, il s’agira de s’appuyer sur les processus métiers déjà connus dans l’entreprise (saisie et emploi des données dans les différents services), sur les systèmes utilisant ces données et sur les démarches de gestion des risques de l’entreprise (maîtrise des données personnelles par exemple).
Ainsi, le processus métier modélise chacune des activités des acteurs métiers afin de conceptualiser concrètement les données qui seront ensuite utilisées dans l’organisation. Par exemple, lors de la mise en place d’une offre de crédit dans une banque, le conseiller financier saisit des données (CNI, Salaire, situation familiale, médicale, etc.) servant à l’ensemble du processus.
4 – Favoriser la qualité pour valoriser la donnée
La maîtrise de la donnée, c’est aussi la maîtrise de sa qualité. Car seule une donnée de bonne qualité au début du processus de collecte garantit une qualité du cas d’usage en sortie. Par exemple, un accord de crédit ou un coût d’assurance dépendent des données recueillies et utilisées au départ sur tel ou tel client. C’est à cette seule condition que la performance du service rendu au client mais aussi l’innovation pourra se réaliser, dans le cadre d’un processus industrialisé (mise en production), reproductible et agile.
La qualité des données est déjà mesurée dans de nombreux systèmes informatiques clients, de manière hétérogène et cloisonnée. La mise en œuvre d’une gouvernance de la donnée avancée doit permettre de construire un référentiel des règles de contrôle et de qualité. Ce qui permettra de ne pas dupliquer les contrôles, de concentrer toutes les mesures disponibles, de les complémenter et de mettre en place des plans d’amélioration des données prioritaires.
5 – Faciliter l’intégration des normes et des règlements
Les aspects normatifs et réglementaires sont généralement perçus comme des contraintes, génératrices de coûts. Pour autant, ils peuvent aussi amener les acteurs à collaborer entre eux, et représentent ainsi des opportunités de création de valeur.
Or, de nouvelles obligations réglementaires apparaissent continuellement, tout en étant généralement complémentaires aux précédentes. À chaque nouvelle évolution, une data gouvernance efficace consiste à ne pas tout reprendre depuis le début, mais à capitaliser sur les contrôles déjà en place, afin d’identifier les éléments uniquement nécessaires et complémentaires à intégrer pour une mise en œuvre efficiente.
6 – Inscrire la data gouvernance dans le long terme
Nouveaux marchés, nouvelles offres, nouveaux processus automatisés… la donnée, sa captation, ses traitements changent en permanence : si la mise en place d’une data gouvernance est longue et complexe, elle n’est jamais terminée et doit s’inscrire dans le temps long.
Comme dans tout projet de ce type, les premiers cas d’usage doivent permettre de démontrer rapidement une véritable efficacité (« quick win ») pour enclencher la machine. Et c’est au CDO - au travers de tableaux de bord et d’indicateurs - de savoir communiquer sur ces résultats auprès de sa communauté pour continuer de construire une gouvernance des données optimale, pour motiver et multiplier les usages dans la durée.
7 – Installer une culture de partage de la donnée
Dans les entreprises « digital native », telles que les GAFAM ou les start-up, la culture de la donnée est innée. D’autant que c’est généralement sur la donnée que se détermine et se construit la valeur ajoutée de ces nouveaux leaders. Dans les autres entreprises, c’est tout un état d’esprit qu’il faut faire évoluer.
La gestion du changement y est longue et complexe. Elle demande beaucoup de travail de persuasion de la part des CDOs, qui doivent s’appuyer sur des cas d’usage réussis pour créer le réflexe du partage de la donnée (data literacy) et ainsi favoriser l’innovation et offrir de nouveaux avantages concurrentiels à l’entreprise.
Le rôle de la Data Governance est donc de favoriser la transformation de l’entreprise, sa pérennité et son renouvellement nécessaire face aux disruptions et évolutions de marché.
En d’autres termes, le plus grand défi des CDOs est d’éveiller les consciences pour que toutes les parties-prenantes se dirigent ensemble vers l’innovation, la création de valeur pour assurer, à terme, la survie et le développement de l’entreprise.
Depuis quelques années, Elon Musk ne cesse de faire des annonces relatives à des avancées technologiques. Voitures autonomes, voyages interplanétaires, interface homme-machine, achat du réseau social Twitter… rien ne semble arrêter l’homme d’affaires. Aucun obstacle technique, géographique, physiologique ne lui semble infranchissable. Pourtant, ses projets pourraient, à court terme, poser de véritables difficultés du point de vue juridique.
La recherche d’une fusion entre le cerveau et l’intelligence artificielle
Des interrogations autour de la notion de « personnalité juridique »
La quête d’une interface entre humains et machines conduit à s’interroger sur ce qui pourrait advenir d’entités qui seraient véritablement en symbiose. La dichotomie entre les personnes et les choses persiste depuis des siècles. Elle structure le droit civil : tout ce qui n’est pas une personne est considéré comme étant une chose. Les premières sont des sujets de droit, c’est-à-dire qu’elles sont titulaires de droits et d’obligations. Les secondes sont soumises à la volonté des premières.
Il faudrait donc déterminer dans quelle catégorie placer ces entités reposant sur la symbiose entre l’homme et la machine. Aujourd’hui déjà, il est acquis que la « personnalité juridique » n’est pas seulement l’apanage des personnes humaines : les sociétés, par exemple, disposent de la personnalité morale. Elles ont ainsi des droits liés à leur personnalité juridique technique.
Certains proposent également de mobiliser cette construction juridique qu’est la « personnalité juridique » pour protéger les animaux.
Cette fiction pourrait-elle à l’avenir permettre d’accorder des droits à ces interfaces homme-machine ? Si oui, il faudrait encore déterminer de quels droits elles pourraient bénéficier. Certains droits visent en effet spécifiquement l’humain qui est en chaque individu. Les accorder à des entités mi-homme mi-machine serait un non-sens. À titre d’exemple, le respect de la dignité humaine impose de préserver l’intégrité génétique des personnes humaines. Une telle protection ne serait pas envisageable dans les mêmes termes pour ces nouvelles entités.
À l’instar de l’hybride entre l’homme et l’animal, l’hybride entre l’homme et la machine serait une sorte de chimère, c’est-à-dire, un être composé de parties disparates formant un ensemble sans unité.
Une telle hybridation interroge les limites de la personnalité juridique. Si la partie technologique de l’entité intervient dans des proportions très importantes, il paraît difficilement concevable de lui attribuer la personnalité juridique dans les mêmes termes qu’à la personne humaine. Surtout, si le corps humain ne devient que le support de la machine, dirigée par l’intelligence artificielle, cette entité disposerait-elle toujours de la personnalité juridique ? Suivant la règle selon laquelle l’accessoire suit le principal, le corps, accessoire de la machine, devrait répondre au même régime : cette entité, même en disposant d’un corps humain, serait une chose, non une personne.
La particularité des implants cérébraux
Les implants cérébraux développés dans le cadre de Neuralink ne peuvent pas être traités comme n’importe quelle prothèse qui serait implantée dans le corps humain. Certes, le projet traite aujourd’hui de l’utilisation d’implants à des fins thérapeutiques.
Surtout, si les décisions ne sont pas prises de manière autonome par la personne humaine, mais plutôt supplantées par l’intervention de l’intelligence artificielle, cette dernière ne devrait-elle pas être titulaire de droits et, surtout, d’obligations ? Pourtant, dès lors qu’il ne s’agit que d’une chose, elle n’est qu’objet de droit.
La crainte d’un glissement dans l’usage des implants cérébraux
En somme, l’expérimentation d’implants cérébraux à des fins thérapeutiques est une chose, leur utilisation à des fins de symbiose entre l’homme et la machine en est une autre. Ces deux situations doivent être distinguées car elles ne répondent pas aux mêmes règles de droit.
Dans le premier cas, les implants pourraient être regardés comme des dispositifs médicaux, expérimentables sur l’homme, à des fins d’amélioration de sa santé. Dans le second cas, il s’agirait d’opter pour une augmentation des capacités humaines et donc, de s’inscrire dans le courant transhumaniste auquel Elon Musk semble appartenir. La difficulté qui se pose donc aujourd’hui face aux projets du multimilliardaire est donc de freiner de telles velléités transhumanistes. Menées à bien, ces ambitions poseraient de sérieuses difficultés en termes d’attribution de la personnalité juridique et, par conséquent, de responsabilité s’agissant des actes qui pourraient être réalisés par ces entités mi-homme mi-machine.
La multiplication des risques par l’usage des technologies
Plus encore, qu’adviendrait-il en cas de biohacking de l’implant ? Déjà, la série Biohackers a permis de souligner que les progrès scientifiques pouvaient conduire à des manipulations du génome à des fins criminelles.
Dans le cas de l’implantation cérébrale de puces disposant d’une intelligence artificielle, le hacking pourrait être particulièrement dangereux. Certains estiment d’ailleurs qu’une intelligence artificielle hackée serait une arme, permettant l’essor du cybercrime.
Pour consulter un médecin, faire ses courses, ou appeler une entreprise, nous avons tous déjà perdu de précieuses minutes dans une file d’attente. L’expérience pénible de l’attente a conduit de nombreux services à réfléchir à ses causes et éventuellement trouver des solutions pour la réduire. Pour comprendre l’attente, la théorie des files d’attente, née en 1917 à la suite des travaux d’Erlang, a servi à modéliser mathématiquement ce processus, qui conduit des individus à ne pas être servis directement.
Commençons alors par une simple question : pourquoi est-ce qu’on attend ?
Imaginons une caisse de supermarché avec un agent qui sert chaque client en 5 minutes et où un client arrive toutes les 6 minutes. Ce système n’induira a priori aucune attente comme chaque client verra l’agent libre au moment de son arrivée à la caisse. Imaginons maintenant qu’un client arrive toutes les 4 minutes. Le premier client de la journée n’attendra pas, le second client attendra 1 minute, le troisième 2 minutes, le quatrième 3 minutes et ainsi de suite, si bien que la file d’attente va s’allonger indéfiniment.
Dans une telle situation, le système devient instable et ne permet pas d’atteindre un régime d’équilibre. Ces deux exemples suggèrent qu’à long terme, on ne devrait constater que des files infiniment longues ou totalement vides… ce qui est loin d’être le cas !
À la source de l’attente : la variabilité
Il manque dans ces deux exemples l’ingrédient principal de l’attente : la variabilité. Les temps de service et d’interarrivées sont en réalité aléatoire, ce qui induit par moment des arrivées concentrées, par moment des services long, et conduit à des alternances entre périodes de file vide et périodes de file congestionnée. Ainsi, même si le temps de service est plus court en moyenne que le temps d’interarrivée, certains clients vont attendre.
La théorie des files d’attente permet de modéliser cet aléa et de calculer l’attente moyenne qu’un client devrait subir en fonction de paramètres comme le temps moyen de service, le temps moyen entre deux arrivées ou le nombre d’agents en service. Ces formules permettent de mieux comprendre les causes de l’attente et d’aider à la prise de décision lorsque l’intuition manque.
Quelle caisse choisir ? Celle pour moins de 10 articles !
Parmi ces questions, vous vous êtes peut-être déjà demandé vers quelle caisse aller dans un supermarché.
Si les deux caisses sont quasi-identiques, le choix n’a pas d’impact sur l’attente, mais on peut se trouver dans la situation où une des caisses est spécialisée « moins de 10 articles », et l’autre est une caisse normale. Dans ce cas, le temps moyen d’attente estimé, qui est égal au nombre de clients devant vous multiplié par leur temps de service, n’est pas forcément l’unique indicateur. Il y a aussi la variabilité des services qui compte. Les formules mathématiques montrent qu’une série de service court est moins variable que quelques services plus longs.
Ainsi, même si l’attente moyenne est identique, il vaut mieux choisir la caisse pour moins de 10 articles, car cette caisse vous offre la plus grande chance de sortir vite du magasin.
Être peu mais rapides ou nombreux et plus lents ?
Une autre question : est-ce qu’il vaut mieux embaucher peu d’agents rapides ou beaucoup d’agents lents (sans prise en compte des coûts salariaux) ? On pourrait penser que cela revient au même d’avoir un agent qui sert chaque client en 1 minute ou 10 agents qui servent chacun un client en 10 minutes. Or ce n’est pas le cas. Il vaut mieux embaucher peu d’agents rapides.
La théorie des files d’attente modélise les situations où certains agents ne travaillent pas du fait de l’absence de client dans la file, ce qui arrive plus souvent quand il y a beaucoup d’agents, comme plus de clients peuvent être servis simultanément. Dans ces situations, la performance de la file n’est pas optimale, ce qui conduit à des performances dégradées avec de nombreux agents lents en comparaison d’une situation avec peu d’agents rapides.
Faut-il réguler le flux des clients entrant au supermarché ?
Il est clair que l’attente augmente avec le volume des arrivées et avec le temps de service. On peut se demander ce qui est le pire : voir une augmentation des arrivées ou subir un ralentissement des services ? Les deux phénomènes semblent assez équivalents. Pour autant, les formules montrent que pour un même taux d’occupation, défini comme la proportion de temps pendant laquelle un agent sert des clients, il est pire d’avoir des services lents. Il n’y a pas d’intuition claire derrière ce résultat, pour autant les conséquences managériales sont importantes, conduisant les entreprises à mettre plus d’effort dans le maintien d’une productivité au travail, plus que dans une régulation des flux entrants.
En résumé, la théorie des files d’attente est un outil puissant qui permet de prendre des décisions concernant le routage des clients, le nombre d’agents à embaucher, et la conception d’un système de service. Comme l’attente concerne la plupart des services, des plus quotidiens comme les supermarchés, les centres d’appels et les systèmes de partage de vélo, aux plus fondamentaux comme les urgences hospitalières, les outils de ce champ d’études ne cessent de se développer pour aider à des prises de décisions plus efficaces.













{kind=link}