Avez-vous repéré ce qui distingue cette main de celles que vous voyez habituellement ? Comptez donc le nombre de doigts…
La main porte un « sixième doigt artificiel » robotique que nous avons développé avec notre collaborateur, le professeur Yoichi Miyawaki de l’Université d’électro-communication de Tokyo au Japon.
Les utilisateurs peuvent contrôler ce sixième doigt indépendamment de leurs autres doigts. En effet, nous pouvons isoler, avec un algorithme, la partie de l’activité musculaire de l’avant-bras qui ne contribue pas aux mouvements de nos doigts habituels, et utiliser ce signal pour contrôler le doigt robotique.
Il est de plus équipé d’un capteur « haptique » (qui désigne le sens du toucher) : celui-ci sent ce que sentirait un doigt et calcule un « retour haptique », c’est-à-dire de légères déformations qui sont appliquées sur la paume de la main et génèrent des sensations tactiles.
L’utilisateur peut manipuler ce membre surnuméraire avec un minimum d’apprentissage – après moins d’une heure d’utilisation pour de nombreuses personnes. Pratique pour jouer du piano !
Nous étudions ainsi comment notre corps réagit face à de nouveaux membres – c’est aussi ce qui est nécessaire quand celui-ci doit accepter une prothèse par exemple.
Plus précisément, nous avons demandé aux utilisateurs de toucher une ligne cible avec leur propre petit doigt (sans voir leurs doigts), et cette expérience a montré que les utilisateurs deviennent en fait incertains quant à l’emplacement de leur propre petit doigt dans l’espace.
Nous poursuivons actuellement ces études afin d’observer directement les modifications potentielles de l’activité cérébrale des utilisateurs utilisant l’imagerie par résonance magnétique fonctionnelle, liée à la représentation de leur sixième doigt robotique. Par exemple, on peut chercher à déterminer quelles zones du cerveau s’« activent » lorsque l’utilisateur bouge le doigt.
Un autre exemple frappant est celui de l’« illusion de la main en caoutchouc », où un utilisateur craint que l’on ne lui tape sur la main alors que son « vrai » bras est ailleurs.
Le cerveau humain peut adopter des membres étrangers
Cet exemple et d’autres étudesscientifiques réalisées au cours des dernières décennies, y compris les nôtres, ont montré qu’il est en fait assez facile de tromper notre cerveau en lui faisant croire que d’autres membres artificiels font partie de notre corps : celui-ci est très adaptable et flexible, dans ce qu’il définit et accepte comme étant notre corps.
Cette flexibilité est bien utile, car le corps humain change à mesure que nous grandissons et vieillissons. Les changements physiques peuvent également être causés par des accidents ou des paralysies, auxquels nous sommes potentiellement capables de nous adapter.
Cette notion d’« incarnation » est aussi ce qui nous permet d’accepter des prothèses pour remplacer ou compléter des fonctions perdues.
Des limites à l’acceptation d’un nouveau membre ?
Avec nos études sur les membres surnuméraires comme le sixième doigt, nous nous intéressons aux limites de cette acceptation. Est-il possible d’ajouter de nouveaux membres à notre corps inné ? Et pouvons-nous encore sentir les membres ajoutés comme faisant partie de notre corps ?
Plusieurs études antérieures ont tenté de répondre à cette question en attachant des membres artificiels supplémentaires, par exemple des doigts robotiques, des bras et une queue virtuelle à des humains.
Cependant, toutes ces tentatives se sont appuyées sur le « remplacement d’un membre » où le membre ajouté est actionné par les mouvements d’un membre existant et tout retour haptique sur le membre ajouté est fourni au membre existant – remplaçant en fait ce membre existant par un nouveau membre artificiel.
Dans notre étude, nous cherchons à savoir si notre cerveau peut accepter un membre supplémentaire vraiment indépendant, qui peut être déplacé indépendamment de tout autre membre, et à partir duquel nous pouvons obtenir des retours haptiques, indépendants de tout autre membre. Il semblerait que oui.
Ainsi, du point de vue applicatif, nos résultats, à savoir que des membres supplémentaires peuvent être acceptés par notre cerveau, sont encourageants pour le développement futur de membres artificiels portables.
Une nouvelle étude menée par Usercentrics, leader mondial dans le domaine des plateformes de gestion des consentements (CMP), a révélé que 90 % des jeux mobiles ne respectaient pas les règlements sur la protection de la vie privée. Cela signifie que des millions de joueurs n'ont aucun contrôle sur la façon dont leurs données personnelles sont utilisées.
« Malgré la menace de lourdes sanctions en cas de manquement et la volonté de plus en plus forte des consommateurs d'exercer leurs droits sur leurs données personnelles, l'étude démontre clairement que la plupart des éditeurs de jeux mobiles continuent à privilégier leurs bénéfices plutôt que la protection de la vie privée », déclare Valerio Sudrio, Directeur Mondial des Solutions d'Applications chez Usercentrics. « Les app stores, les annonceurs publicitaires et les grandes marques poussent le secteur vers un avenir où le consentement est omniprésent. Les développeurs et les éditeurs doivent donc prendre conscience que la conformité des données (données personnelles et consentement) sera leur atout le plus précieux. »
L'étude a examiné un large éventail des meilleurs jeux iOS et Android, en particulier ceux qui comptaient au moins 150 000 utilisateurs actifs par jour, pour un total de 269 jeux. Les données ont été collectées à l'aide de l'outil d'audit Apptopia. Les résultats ont montré qu'une grande majorité (environ 94 %) des jeux mobiles dans la zone EMEA et d'Amérique du Nord (environ 86 %) collectent des données personnelles sans demander le consentement des utilisateurs. Il s'agit d'une violation du Règlement Général sur la Protection des Données (RGPD) de l'Union européenne et de la Directive ePrivacy.
Les résultats de l'étude montrent que les développeurs de jeux mobiles ne sont pas en phase avec la tendance générale du secteur, qui est d'adopter une approche de la collecte de données basée sur le consentement. Par exemple, Apple a lancé l'année dernière son système App Tracking Transparency (ATT), qui permet aux utilisateurs d'avoir un meilleur contrôle sur leurs données et leur confidentialité. Google développe actuellement son propre système équivalent. En outre, obtenir le consentement des utilisateurs est crucial pour générer des revenus, car 40 % des joueurs ont déclaré qu'ils désinstalleraient un jeu s'ils avaient des inquiétudes concernant la protection de leurs données.
La majorité des éditeurs et des développeurs de jeux mobiles n'ont intentionnellement pas intégré le consentement craignant un impact négatif sur leur chiffre d'affaires. Cependant, avec l'insistance grandissante des grandes marques et des annonceurs publicitaires pour une utilisation de données conformes, les développeurs de jeux doivent intégrer le consentement pour pérenniser leurs stratégies de monétisation avec la publicité In-App (IAA).
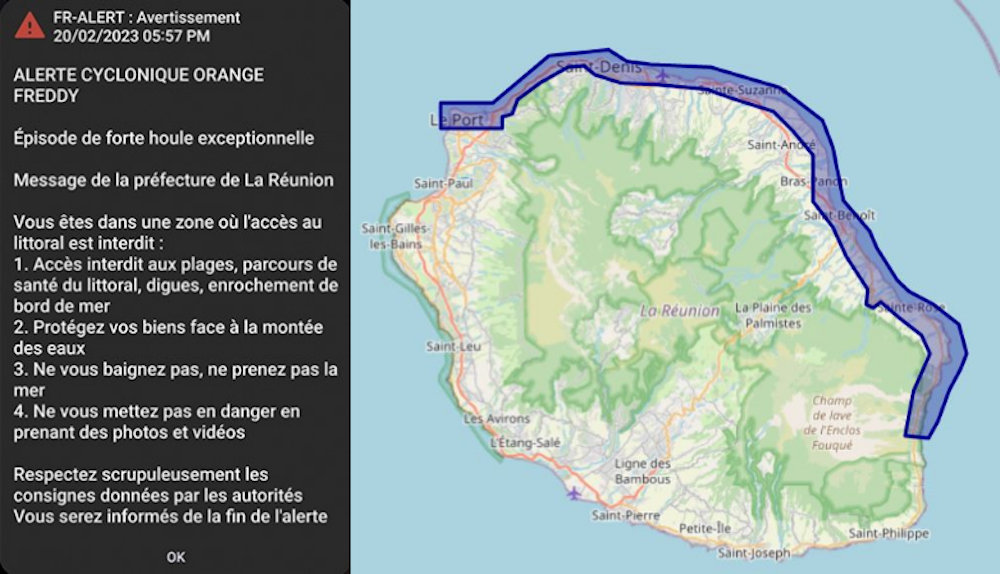
Envoi d’une notification FR-Alert lors du passage du cyclone Freddy au large de la Réunion le 20 février 2023, et zone de diffusion de la notification.Fourni par l'auteur
La plateforme d’alerte multicanal FR-Alert, disponible depuis juin 2022, permet désormais aux autorités d’envoyer des notifications sur les téléphones portables des personnes présentes dans une zone de danger.
Dans ces messages, les autorités peuvent indiquer la nature du danger, le secteur géographique concerné et les consignes de mise en protection. L’envoi des notifications se fait par diffusion cellulaire (cell broadcast) via les antennes relais des opérateurs de téléphonie, sans risque de saturation.
FR-Alert, un dispositif sous-employé
La diffusion d’un signal d’alerte doit répondre à une situation de danger susceptible de porter atteinte à l’intégrité physique des biens et des personnes.
Concernant FR-Alert, cette diffusion est sous la responsabilité du ministère de l’Intérieur et des préfets (qui ont accès aux moyens techniques de les déployer sur les départements dont ils ont la charge). Les maires (responsables de l’alerte à l’échelle communale) peuvent solliciter l’emploi de FR-Alert en formulant une demande justifiée qui devra être validée par le préfet.
Le dispositif est en place depuis juin 2022, et seules 2 notifications (en dehors des 27 exercices) ont été envoyées à ce jour : la première lors des feux de forêt à Landiras le 18 juillet 2022, et la seconde lors du passage du cyclone Freddy à la Réunion le 20 février 2023.
Comment expliquer ce faible nombre d’utilisations de FR-Alert, alors que plusieurs autres évènements nécessitant une mise en protection des populations et une alerte ont eu lieu sur le territoire français depuis son lancement ?
On peut par exemple citer la tempête sur la côte ouest de la Corse (15 août 2022) et l’explosion dans l’enceinte de l’usine Arkema, usine Seveso « seuil haut » à Jarrie (10 novembre 2022). Si la montée en puissance du déploiement de FR-Alert peut expliquer ces non-utilisations, d’autres événements se sont produits dans des zones où le système avait été testé. C’est le cas à Rouen, où FR-Alert a été testé en juin 2022, mais non utilisé lors de l’incendie industriel survenu en janvier 2023.
Le cas de l’accident industriel de Grand-Couronne
Les accidents industriels sont intéressants à analyser du point de vue de l’utilisation ou non de FR-Alert. Ils impliquent en effet la coexistence de trois facteurs qui mettent en tension la gestion de la crise : l’imprévisibilité de l’accident et les difficultés d’évaluer rapidement ses évolutions possibles ; la nécessité de gérer l’urgence pour les industriels et les autorités ; la perception de l’événement par la population. L’emploi (ou non) de FR-Alert doit tenir compte de ces trois facteurs. L’incendie survenu le 16 janvier 2023 à Grand-Couronne, au sud de Rouen, illustre bien cette tension.
L’incendie se déclenche aux environs de 16h30 dans un entrepôt de Bolloré Logistic, qui abrite plus de 12 000 batteries de lithium. Il se propage rapidement vers un entrepôt voisin, dans lequel sont stockés plus de 70 000 pneus.
Les sapeurs-pompiers prennent rapidement connaissance de la nature de ces produits. Ils réalisent alors des mesures d’urgence (détection des vapeurs inorganiques), dont les résultats n’indiquent aucun risque pour les pompiers en intervention et la population riveraine.
Puis, ils réalisent d’autres prélèvements, notamment pour mesurer la présence d’acide fluorhydrique. Il s’agit de huit prélèvements d’air pour l’analyse en phase d’urgence (dont les premiers résultats sont disponibles à 18h56, soit plus de 2h30 après le départ de l’incendie) et de 28 balises placées en différents points de l’agglomération (dont les résultats arrivent un peu plus tôt, à 18h24).
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
Concernant les toxiques de référence – monoxyde d’azote, acide chlorhydrique, acide cyanhydrique et acide fluorhydrique – les valeurs restent en dessous des seuils de détection des appareils de mesure. Ces résultats rassurants auront, selon le préfet, « nourri la conduite opérationnelle de la gestion de crise ».
Ni l’activation de sirènes ni l’envoi de notifications via FR-Alert ne sont alors considérés comme opportuns malgré les incertitudes liées à l’attente des résultats et alors que le préfet reconnaît dans un communiqué de presse que « visuellement, c’était très impressionnant ». L’incendie est en effet visible à plusieurs kilomètres, et de nombreuses vidéos circulent sur les réseaux sociaux. La similarité visuelle avec l’incendie des entrepôts Lubrizol (26 septembre 2019, également à Rouen) est d’ailleurs manifeste, pouvant expliquer cette surmédiatisation.
Une communication lente et contradictoire
La phase d’urgence critique, entre 16h30 et 18h24, est donc une longue période d’incertitudes pendant laquelle la question de l’alerte, de l’avertissement ou de l’information à la population doit se poser.
Or, les premières informations officielles ne seront diffusées à la population qu’à partir de 17h50 (soit près d’1h30 après le début de l’incendie), la première via le compte Facebook de la mairie de Grand-Couronne, suivi de la Métropole Rouen Normandie via les SMS automatiques InfoRisques, puis de nouveau via les comptes Facebook de mairies, avant de terminer par le compte Twitter de la préfecture avec un premier message diffusé à 19h34. Aucune notification FR-Alert ne sera envoyée.
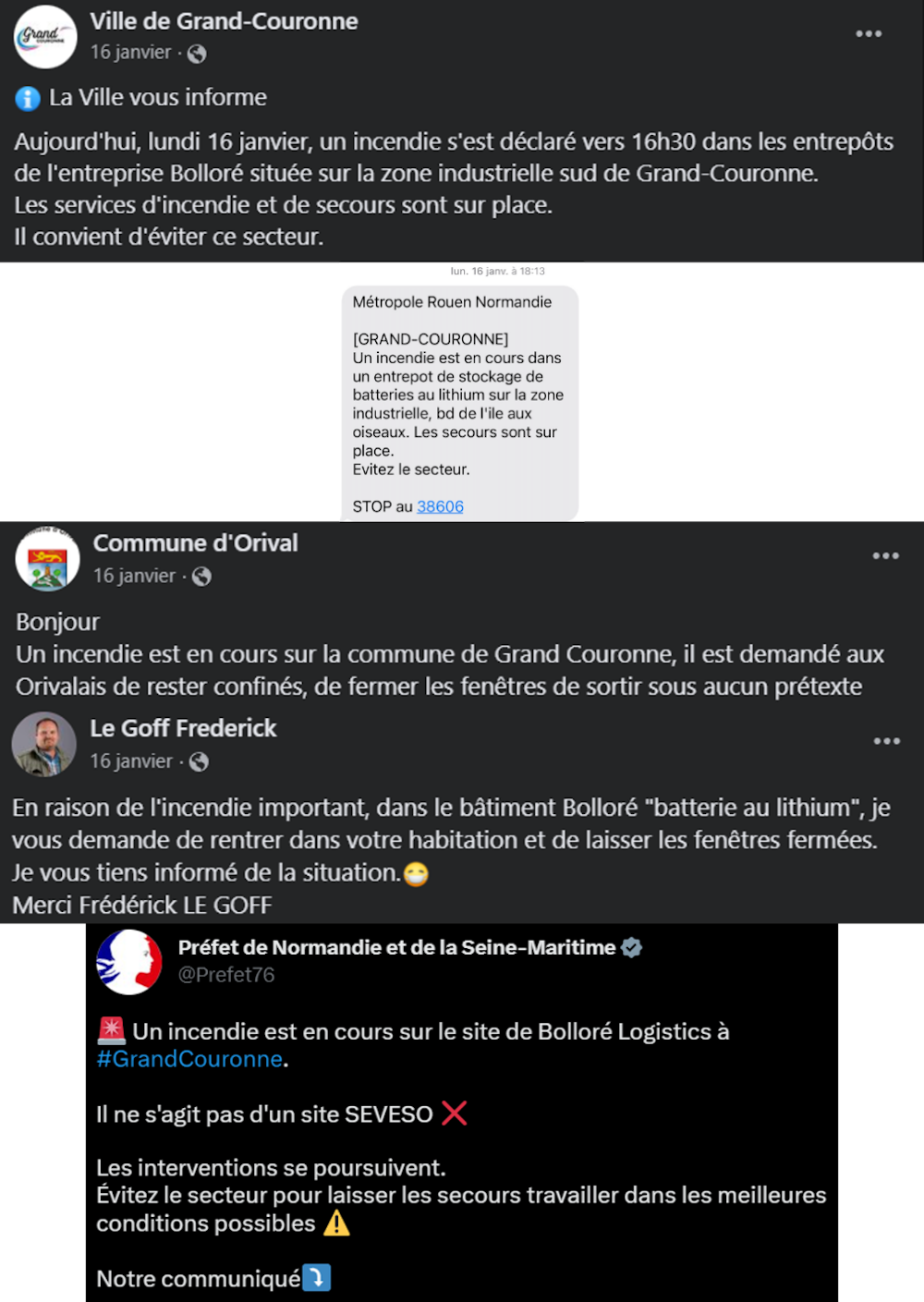
Message Facebook de la mairie de Grand-Couronne (17h50), puis SMS d’information de la métropole Rouen Normandie (18h13), suivi du message Facebook de la mairie d’Orival (18h36) et du maire de Moulineaux (18h36) et finalement la Préfecture (19h34).Fourni par l'auteur
Diversité des modes d’information utilisés, incertitudes quant aux populations ayant reçu les messages, contradictions des informations diffusées : « Évitez le secteur » selon la métropole, « restez confiné » selon la mairie et « Évitez le secteur pour laisser les secours travailler dans les meilleures conditions possibles » selon la préfecture. De quoi semer le trouble au sein de la population !
Quelles utilisations concrètes pour FR-Alert ?
Pourtant, FR-Alert serait techniquement adapté pour diffuser des avertissements et des informations dès le début de cette catégorie d’événements à forte incertitude d’évolution. Ce serait aussi un moyen d’harmoniser les discours, et de réduire la cacophonie qui est générée quand chaque acteur envoie son propre message, parfois contradictoire.
Sauf que FR-Alert n’est pas un outil d’information et encore moins d’avertissement si on se conforte à la doctrine actuelle, qui est de l’utiliser uniquement pour alerter, via des notifications, les personnes situées dans une zone confrontée à un danger. Tout dépend alors de la façon d’interpréter « zone de danger »…
La doctrine doit donc s’adapter aux besoins des populations, les cibles finales de FR-Alert. Trois perspectives à court terme doivent être discutées :
1/L’alerte ne doit plus être dissociée de l’avertissement et de l’information, qui en sont des nuances. Avertir ou informer le plus vite possible sur une situation potentiellement à risque, pouvant par essence devenir dangereuse, est indispensable. Si un événement prend de l’ampleur, est vu et/ou entendu sur plusieurs kilomètres, déclencher FR-Alert au titre d’un avertissement peut d’autant plus s’avérer utile si l’on doit rapidement passer à des mesures de protection radicale (comme le confinement ou l’évacuation). Le niveau 4 (Avertissement) prévu dans le système devrait pouvoir être utilisé dans ce contexte.
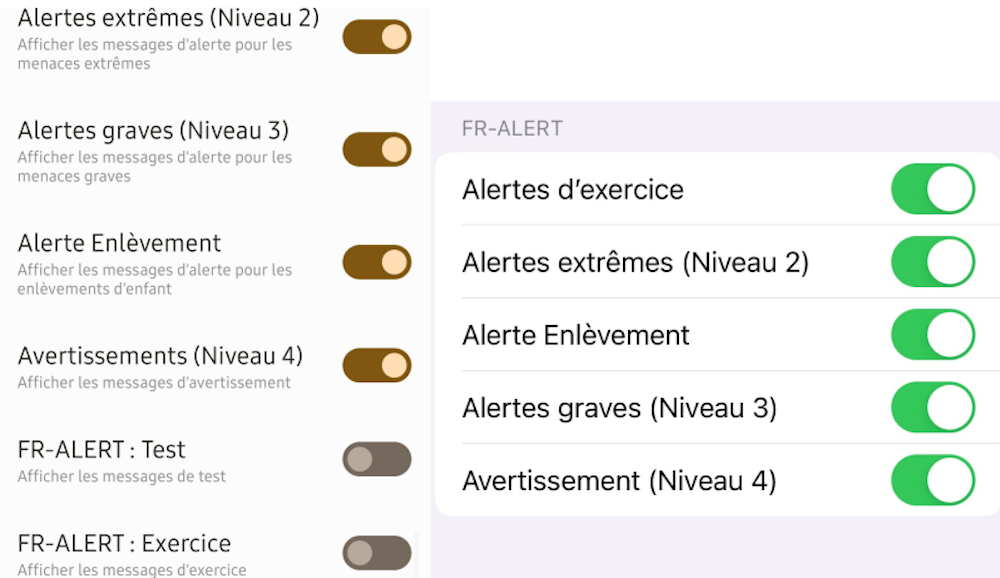
Notifications possibles via FR-Alert sur un système d’exploitation Android (à gauche) et IOS (à droite).Fourni par l'auteur
2/L’alerte peut et doit être levée dès que l’absence d’un danger est confirmée. Pour cela, il faut accepter les « fausses alertes » (c.-à-d. diffuser un signal d’alerte non suivi d’un danger réel), ce qui va à l’encontre des habitudes (prises du côté des autorités mais aussi de la population). Il faudrait aussi assouplir les conséquences pénales, notamment pour les maires, l’ordonnance du 19 septembre 2000 et la circulaire du 28 septembre 2011 stipulant que communiquer ou divulguer une fausse information faisant croire à un sinistre est passible de 30 000 euros d’amende et de 2 ans d’emprisonnement. Il faut donc passer d’une crainte de « l’alerte pour rien » à un plébiscite de « l’avertissement pour éviter le pire » : rumeurs, défiance envers les autorités, absence d’anticipation en cas d’aggravation de la situation.
3/L’absence d’information, rapide et au plus près de la crise, a pour effet d’accroître la défiance vis-à-vis des autorités et des acteurs publics. À la place d’un discours vite rassurant, sans doute proportionné aux mesures de protection nécessaires en phase d’urgence, mais qui perturbe l’appréciation qu’en a la population, il faut accepter l’existence d’incertitudes et préparer la communication qui va avec. Il faut aussi accepter de demander à la population qu’elle reste à l’abri le temps de réaliser les vérifications nécessaires.
Rappelons que les catastrophes résultent souvent de prises de décisions tardives, de communications hasardeuses et contradictoires et de la difficulté de partager en amont de la crise des informations entre l’ensemble des partenaires. Autant de problématiques qu’un emploi plus judicieux de FR-Alert pourrait en partie résoudre…
La stagnation des salaires, l’inflation record, la chute de la consommation des ménages viennent aujourd’hui considérablement redistribuer les cartes de notre société de consommation. Une stratégie utilisée par les sites de vente peut particulièrement renforcer ces phénomènes. On la nomme la tarification dynamique en ligne. Il s’agit d’une stratégie de variation incessante des prix à la hausse et à la baisse, à laquelle de plus en plus de sites ont recours pour des catégories différentes de produits ou de services.
À titre illustratif, cette méthode a été utilisée par le site Ticketmaster pour distribuer les billets des concerts de Bruce Springsteen dans le cadre de sa tournée 2023, avec des prix qui sont montés jusqu’à 5 000 dollars pour les places les plus prisées, menant les fans à s’insurger.
Certains billets pour les concerts de la tournée 2023 de Bruce Springsteen ont été mis à prix à 5 000 dollars.Andrés Fevrier/Flickr, CC BY
Nos travaux de recherche invitent particulièrement à envisager les conséquences que la tarification dynamique en ligne peut avoir sur les achats des consommateurs. Comment fonctionne-t-elle ? Quand leur profite-t-elle ou nuit-elle à leurs achats ? Quelles sont les options dont ils disposent pour la limiter ?
Comment ça marche ?
La tarification dynamique en ligne repose principalement sur le recours à des algorithmes d’intelligence artificielle utilisés pour orchestrer une fluctuation des prix pour un même produit ou service au cours du temps. Cette stratégie utilise, entre autres, des données relatives aux consommateurs (comme les fameux cookies collectés en ligne ou les informations volontairement données lors d’une inscription en ligne sur un site comme le nom ou l’âge) et les données du marché (comme les prix pratiqués par les concurrents). Cette méthode de fixation des prix permet, par exemple, à des sites de vente de réaliser une variation des prix en temps réel à l’instar d’Amazon, de Cdiscount ou de la Fnac.
L’automatisation algorithmique de la fixation du prix peut même devenir la base du modèle économique de certaines entreprises. Par exemple, pour l’application Uber, le prix est fixé instantanément selon l’offre et la demande, en s’appuyant, entre autres, sur la planification informatisée des courses demandées par les clients et du nombre de chauffeurs disponibles à ce moment-là pour une zone géographique donnée.
L’objectif premier d’une entreprise qui a recours à la tarification dynamique est de maximiser son profit. Ce dernier est encore plus optimisé lorsque cette méthode repose sur une personnalisation du prix pour chaque consommateur. Dans ce cas, l’algorithme utilisé mobilise, entre autres, son « consentement à payer » (correspondant au montant maximal qu’il est prêt à payer pour un produit), critère qui découle d’un calcul algorithmique prenant par exemple en compte son historique d’achats.
Le consommateur, gagnant ou perdant ?
Dans le cadre de la tarification dynamique en ligne, on peut légitimement se demander dans quelle mesure une variation continue des prix pour un produit identique mène le consommateur à se sentir gagnant ou perdant…
Deux formes extrêmes de tarification dynamique peuvent être identifiées. La première est une forme basique où le prix du produit ou du service proposé varie dans le temps de la même façon pour tous les consommateurs. La seconde forme est totalement personnalisée c’est-à-dire qu’un prix différent est appliqué à chaque consommateur en se basant sur l’estimation algorithmique de son « consentement à payer ». Dans ce second cas, les consommateurs se voient proposer au même moment des prix différents pour un article identique. L’évaluation du consentement à payer peut ne pas être le reflet de la réalité économique et sociale des individus. L’algorithme peut donc conduire à une surestimation de ce paramètre qui peut être perçue comme injuste par les individus et donc les mener à se sentir perdants.
De façon générale, quelle que soit l’approche utilisée pour la tarification dynamique en ligne, lorsqu’un prix est perçu comme élevé, le consommateur se voit comme perdant, à l’image des réactions des fans qui ne pouvaient s’offrir les places pour un des concerts de Bruce Springsteen. Tandis que lorsqu’il paie un prix qu’il perçoit comme bas, le consommateur en ressort gagnant.
Que peut faire le consommateur ?
Des outils traqueurs de prix se développent pour aider les consommateurs à retrouver l’historique des prix pratiqués par certaines plates-formes comme Amazon afin de décider si leur achat est à réaliser maintenant ou s’ils prennent le pari d’attendre. Il est également possible de trouver des sites qui aiguillent les consommateurs lors d’achat de produits particuliers quand la tarification dynamique en ligne devient fréquemment utilisée dans certains domaines comme pour les places de concert.
Les consommateurs peuvent aussi essayer autant que possible de limiter les données que les sites peuvent collecter en n’autorisant pas la collecte de cookies lorsqu’ils visitent un site. Ils peuvent aussi éviter de donner toutes les informations demandées lorsqu’ils saisissent un formulaire d’inscription. Il est également envisageable d’effectuer certains achats lorsque ce n’est pas la saison afin de s’assurer que la demande de produits est faible à l’instar de l’achat d’un parasol ou d’un barbecue en hiver.
Évidemment, la tarification dynamique soulève également la question de la responsabilité des entreprises. Ces dernières doivent s’interroger sur les limites des différents algorithmes auxquels elles peuvent avoir recours en intégrant les préoccupations des consommateurs. Par exemple, un enjeu pour les sites est de trouver comment minimiser les biais liés aux algorithmes qui peuvent engendrer des prix amenant à surévaluer le « consentement à payer » des individus. Pour chaque type de produit ou service, il s’agirait donc de s’interroger aussi sur les intervalles de variation de prix et les fréquences de changement du prix perçus comme acceptables par les potentiels acheteurs.
Par ailleurs, certains sites affichent officiellement le recours à cette stratégie à l’image d’Uber tandis que d’autres, tel qu’Amazon, décident de ne pas partager les secrets de fabrication de l’algorithme utilisé. À l’ère où les consommateurs appellent les entreprises à plus de transparence, les préoccupations éthiques des entreprises permettant aux individus de ne pas se sentir lésés en comprenant mieux les prix qui leur sont proposés lors de l’achat d’un produit peuvent finalement apparaître comme essentielles et s’avéraient être un atout stratégique.
Depuis l’incendie qui a ravagé Notre-Dame de Paris le 15 avril 2019, des centaines de chercheurs sont mobilisés afin d’étudier les vestiges de la cathédrale et collaborer à sa restauration.
À côté des groupes de travail du chantier scientifique, centrés sur le bâtiment (pierres, vitraux, charpente) et son architecture, une trentaine d’historiens et de conservateurs, rassemblés au sein du projet ANR e-NDP, « Notre-Dame de Paris et son cloître », étudie spécifiquement la documentation textuelle de la cathédrale, les livres qui composaient sa bibliothèque et les archives manuscrites.
Registres capitulaires du chapitre cathédral de Notre-Dame (Archives nationales).Isabelle Bretthauer, Fourni par l'auteur
Une documentation très riche
Il existe une source essentielle pour connaître l’histoire de Notre-Dame : les registres rédigés, entre le XIVe et le XVIIIe siècle, par les chanoines, c’est-à-dire les clercs qui assistent l’évêque de Paris pour exercer le culte dans la cathédrale et pour gouverner le diocèse. Au nombre de 51, ces chanoines composent ce qu’on appelle le chapitre de Notre-Dame, en charge du Trésor et de la liturgie dans l’église cathédrale.
Au-delà du culte, les chanoines détiennent l’autorité sur le quartier de la cathédrale, ont la tutelle de l’Hôtel-Dieu, l’un des hôpitaux les plus importants du royaume, situé à quelques pas de la cathédrale, et administrent les villages et les terres détenus par la cathédrale en Île-de-France.
Le chapitre de Notre-Dame constitue donc une institution puissante, autonome de l’évêque de Paris et en lien direct avec les autres pouvoirs de l’époque (la municipalité de Paris, l’université, les nobles, les évêques, le roi de France, le pape).
Trois fois par semaine, les lundi, mercredi et vendredi, les chanoines se réunissent pour prendre des décisions relatives à la cathédrale et à son patrimoine. Le notaire du chapitre est chargé d’écrire dans un registre la date de la réunion, la liste des présents et les conclusions des délibérations. 26 registres ont été conservés pour la période médiévale, de 1326 à 1504, soit plus de 14 600 pages de texte manuscrit latin.
Les chanoines statuent sur des questions très diverses : administration de la cathédrale et de son patrimoine, réception des nouveaux chanoines, dons de livres, affaires de discipline, liturgie, gestion des possessions et des droits du chapitre… Ainsi, en 1476, la cloche Gabriel, endommagée, est refaite et remontée dans la tour Guillaume de la cathédrale. Pour sa réfection, le chapitre paye 11 écus d’or.
On estime que les chanoines prennent entre 500 et 1 500 décisions par an. Bien connue des spécialistes de l’histoire de la cathédrale, cette documentation est si massive et si mal indexée qu’elle restait sous-utilisée.
L’intelligence artificielle au service des historiens
Rechercher une information dans ces registres exigeait jusqu’à présent de lire la totalité des décisions ou de se contenter des extraits collectés par des archivistes du chapitre depuis le XVIIe siècle.
Afin d’exploiter de manière exhaustive cette documentation massive et hétéroclite, notre projet utilise les ressources de l’intelligence artificielle (IA), pour transcrire intégralement les registres et pour exploiter leur contenu afin d’éclairer le rôle économique, culturel et social du chapitre de Notre-Dame.
Les 26 registres médiévaux ont d’abord été numérisés (ils sont disponibles sur le site des Archives nationales. Puis l’équipe de recherche a mis au point une intelligence artificielle dite de « handwriting text recognition » (HTR), c’est-à-dire de reconnaissance des écritures manuscrites et de transcription automatique du texte. S’il existait déjà des modèles algorithmiques entraînés à lire des livres imprimés ou des écritures anciennes livresques, très lisibles car très normées et régulières, aucun modèle n’existait pour les écritures cursives de notaires qui prennent des notes à la volée, abrègent les mots latins et écrivent très mal !
Quatre étapes de travail : (1) numérisation du registre, (2) reconnaissance et segmentation des lignes de texte, (3) reconnaissance des zones de textes, (4) transcription automatique en utilisant le modèle via la plate-forme eScriptorium (AN, LL 117, p. 5).Fourni par l'auteur
Postdoctorant à l’École nationale des chartes et désormais chercheur à l’université de Luxembourg, Sergio Torres Aguilar a entraîné des modèles spécialement conçus pour les registres de Notre-Dame, l’un de reconnaissance des zones de texte (dont la mise en page varie au fil des registres), l’autre de lecture. Pour cela, il a utilisé des données préexistantes (des textes de la même époque déjà transcrits et associés à des images) et s’est appuyé sur une cinquantaine de pages de registres du chapitre, transcrites préalablement par les chercheurs. Cette base de textes avec des écritures des XIVe-XVe siècles a permis d’entraîner l’intelligence artificielle.
Au total, sept versions du modèle algorithmique de lecture ont été successivement développées à partir du travail collectif fourni par l’équipe de transcripteurs, réunissant une quinzaine d’historiens spécialistes de Paris, du livre, des institutions religieuses, de l’édition textuelle et des humanités numériques.
[Près de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui]
L’équipe a testé, corrigé et éduqué l’IA à partir de la plate-forme de transcription automatique de documents eScriptorium, afin d’améliorer progressivement les performances de lecture et d’aboutir à la meilleure transcription possible.
L’IA bute sur des obstacles tels que la segmentation des mots (lorsque le passage d’une ligne à une autre oblige le notaire à couper un mot), l’hétérogénéité des manuscrits (différences de mises en pages ou d’écritures) ou l’état des manuscrits (pages déchirées, taches, humidité).
Au final, le modèle produit est parvenu à transcrire 90 % du texte des registres, le taux de reconnaissance oscillant selon les volumes entre 88 et 94 %. Le site du projet e-NDP (en construction) permettra d’explorer le corpus textuel acquis par l’IA, tout en le confrontant aux pages correspondantes des registres qui ont été numérisées. Le modèle facilite la lecture, car il aide l’œil humain à résoudre des difficultés de déchiffrement qui l’auraient beaucoup ralenti. Surtout, l’IA augmente les capacités de lecture et donc le nombre de données collectées. Le modèle sera réutilisable pour toutes les écritures des documents de la pratique de la fin du Moyen Âge.
Notre-Dame révélée
Le corpus textuel acquis par l’IA fait actuellement l’objet de post-traitements et d’un travail d’indexation, notamment par détection automatique des noms de lieux et de personnes.
On peut d’ores et déjà connaître plus précisément les 800 chanoines de Notre-Dame entre 1326 et 1504 et reconstituer leur carrière : présence ou absence aux réunions, responsabilités endossées, types de décisions prises, manquements. Par exemple, en 1392, les chanoines excommunient Robert de Hamelle, chanoine de l’église du Saint-Sépulcre de Paris, qui, en état d’ivresse, a frappé un clerc. Condamné à une amende, le chanoine se voit interdire de boire du vin qui ne serait pas coupé d’eau.
Au-delà des chanoines, les registres permettent de mieux connaître l’histoire des hommes et des femmes qui vivent et travaillent dans le quartier de la cathédrale (des officiers du chapitre aux invités de marque qui logent chez les chanoines, en passant par les servantes au service des clercs). On apprend ainsi qu’en 1420, la garde des enfants trouvés dans l’église de Paris est confiée à Isabelle, veuve de Jean Bruyère, ancien geôlier du chapitre, ou encore que, en 1480, les habitants de Larchant, un village dépendant du chapitre de Notre-Dame et situé à 80 km de Paris, ont détruit le pilori, symbole de la justice des chanoines.
Il est désormais possible d’effectuer des recherches dans des données textuelles massives (« topic modeling ») sur des sujets déjà étudiés ou, au contraire, mal connus, des fêtes liturgiques à l’emploi du plomb dans le bâti, en passant par les rapports entre le roi et les chanoines ou les finances du chapitre.
Le contenu des registres du chapitre pourra être exploité par d’autres projets liés à Notre-Dame, par exemple pour connaître la provenance du bois ou du métal servant à l’entretien de l’édifice. Notre-Dame de Paris comme on ne l’a encore jamais vue !
Ce n’est pas la première fois qu’une étude sur l’exposition des enfants aux écrans (télévision, ordinateurs, consoles, tablettes ou smartphones) est publiée, mais celle qui a été dévoilée hier mérite sans doute davantage d’être observée de près au regard de l’étendue de la cohorte : rien moins que 18 000 enfants.
Les résultats publiés hier sont l’un des volets de l’enquête Elfe (Étude Longitudinale Française depuis l’Enfance), une étude au long cours portée par l’Ined (Institut national d’études démographiques) et l’Inserm (Institut national de la santé et de la recherche médicale) qui suit l’évolution de 18 000 enfants nés en France métropolitaine en 2011 et qui mobilise 150 chercheurs.
Des disparités
Ce vaste panel a permis à ces derniers de décrire « le temps d’écran, total et par type d’écran, des enfants suivis à 2 ans, 3 ans et demi et 5 ans et demi » mais aussi de mettre en avant « des disparités selon la région d’habitation de la famille, son histoire et son origine migratoires, le niveau d’études de la mère et le sexe de l’enfant. »
Les données montrent que le temps d’écran quotidien pour ces enfants était en moyenne de 56 minutes à 2 ans, 1 h 20 à 3 ans et demi et 1 h 34 à 5 ans et demi. Soit des durées bien supérieures aux recommandations de l’Organisation mondiale de la santé (OMS) ou de l’Académie américaine de pédiatrie, qui préconisent de ne pas exposer les enfants de moins de 2 ans aux écrans, puis de limiter ce temps à 1 heure par jour entre 2 et 5 ans.
« En France, la limite d’âge « sans écran » a tendance à être fixée à 3 ans, sous l’impulsion des balises « 3-6-9-12 » proposées en 2008 par le Dr Serge Tisseron, puis de l’Autorité de régulation de la communication audiovisuelle et numérique (Arcom, ex-CSA). Depuis 2019, le Haut Conseil de la santé publique et l’Académie nationale de médecine recommandent de ne pas exposer les enfants de moins de 3 ans aux écrans, si certaines conditions ne sont pas réunies (présence d’un adulte, interactivité). Enfin, Santé publique France (par l’intermédiaire du Plan national nutrition santé) et l’Anses fixent quant à elles l’âge limite à 2 ans », souligne l’étude qui est aussi particulièrement pertinente dans son détail des disparités sociologiques ou géographiques.
Ainsi, les enfants dont la mère est née au Maghreb, en Turquie ou en Afrique subsaharienne passent en moyenne 30 à 50 minutes (selon l’âge) de plus devant des écrans que ceux dont la mère est née en France. Les enfants dont la mère a un niveau collège passent 45 minutes (à 2 ans) et 1 h 15 (à 5 ans et demi) de plus devant des écrans que les enfants dont la mère a un niveau d’études supérieur ou égal à bac +5. Le sexe a moins d’impact : aucune différence n’était observée à 2 ans entre garçons et filles, mais une petite différence émerge ensuite (10 minutes de plus chez les garçons à 5 ans et demi).
La situation géographique joue également : les petits Occitans passent par exemple moins de temps devant les écrans que leurs camarades des Hauts-de-France (46 minutes par jour contre 64 à 2 ans, 69/84 à 3 ans et demi, 79/103 à 5 ans et demi).
Nécessité d’une prévention précoce
Les auteurs reconnaissent quelques limites à leur étude, notamment le fait que les mesures de temps d’écran sont des données déclaratives par les parents et donc potentiellement sous-estimées. Une autre limite concerne les dates de collecte des données : l’enquête à 2 ans s’est déroulée de mai 2013 à avril 2014, celle à 3 ans et demi de septembre 2014 à août 2015, et celle à 5 ans et demi de janvier à septembre 2017.
Depuis, les usages du numérique ont explosé dans les familles, notamment à l’occasion de la crise sanitaire du Covid-19, ce que reconnaissent les chercheurs. « Les écrans portatifs comme le smartphone et la tablette s’étant fortement développés durant la décennie 2010, on pourrait s’attendre à une augmentation du temps d’écran, mais ce serait ignorer que les messages de prévention à l’intention des jeunes enfants se sont eux aussi multipliés sur cette période. »
Cette étude reste cependant importante car elle décrit pour la première fois l’évolution du temps d’écran des enfants sur une longue période, confortant ainsi la nécessité d’une prévention précoce.
Numérique : les Français addicts
L’Arcep et l’Arcom viennent de publier la troisième édition de leur référentiel commun des usages numériques des Français, qui sont de plus en plus connectés au très haut débit sur les réseaux fixes (65 % à la fin du troisième trimestre 2022, + 9 points en un an).
Le référentiel 2023 relève que le téléviseur reste le premier équipement des foyers et que 84 % du parc est connecté à Internet. Le nombre d’utilisateurs de vidéos à la demande par abonnement (Netflix, Prime…) continue de progresser avec 9,4 millions d’utilisateurs quotidiens en moyenne au deuxième semestre 2022. Mais ce sont le e-commerce et les services de communication qui sont de plus en plus utilisés.
D’autres équipements numériques se diffusent également dans la population, selon l’enquête : c’est le cas, par exemple, des enceintes connectées avec assistant vocal ou plus généralement des objets connectés à internet (+7 points par rapport à 2020 pour atteindre 40 %).
Enfin, 82 % des internautes de 11 ans et plus sont équipés d’un smartphone, mais l’usage de l’ordinateur reste prépondérant (62 % en 2022).
(Article publié initialement dans La Dépêche du Midi du 13 avril 2023)
L’Arcep et l’Arcom, qui disposent d'un « Pôle numérique commun », publient la troisième édition de leur référentiel commun des usages numériques. Cette nouvelle édition actualise et complète les données de référence sur les usages et pratiques du numérique en France.
Cette troisième édition du référentiel des usages numériques met en avant de nouvelles thématiques telles que le déploiement des réseaux 5G, l’équipement en objets connectés, l’évolution du trafic internet vers les principaux fournisseurs d’accès à internet, le livestream musical, les usages de recherches de photographies en ligne ou le blocage des sites qui diffusent du sport illicitement.
Très haut débit fixe et mobile : des abonnements en fibre optique majoritaires en France et des usages internet toujours en forte progression
Parmi les enseignements clés, les deux organismes notent la progression toujours importante du nombre d’abonnements au très haut débit sur les réseaux fixes : 65% à la fin du troisième trimestre 2022, + 9 points en un an. Le nombre d’abonnements en fibre optique atteint quant à lui 17,1 millions au 30 septembre 2022, soit 54 % du nombre total d’abonnements à haut et très haut débit (+11points en un an).
Parallèlement, l’usage d’internet continue de progresser fortement. Le trafic entrant vers les principaux fournisseurs d’accès à internet augmente de 25 % en un an au deuxième semestre 2021, une croissance toutefois inférieure à celle du deuxième semestre 2020 (+50%).
Des foyers et individus toujours plus connectés et mieux équipés
Le référentiel 2023 relève que le téléviseur reste le premier équipement des foyers et que 84 % du parc est connecté à Internet. Le nombre d’utilisateurs de VàDA (vidéo à la demande par abonnement) continue de progresser avec 9,4 millions d’utilisateurs quotidiens en moyenne au deuxième semestre 2022. À l’inverse, la consommation illicite diminue de manière notable pour le sport notamment grâce aux mesures prises par l’Arcom pour lutter contre cette pratique (-8 points en 2022), ainsi que pour les films et les séries TV (- 6 points en 2022).
D’autres équipements numériques se diffusent également dans la population : c’est le cas, par exemple, des enceintes connectées avec assistant vocal ou plus généralement des objets connectés. La part des détenteurs d’objets connectés progresse ainsi de 7 points par rapport à 2020 pour atteindre 40%.
Plus globalement, cette édition du référentiel met en exergue le développement de nouvelles pratiques culturelles en ligne : en 2022 près de la moitié des internautes avaient déjà consommé un contenu de livestream musical, dont les offres se sont largement développées pendant la crise sanitaire. L’année précédente, près de 8 internautes sur 10 avaient effectué une recherche de photos sur internet.
Empreinte environnementale
En 2020, le numérique représente 2,5 % de l’empreinte carbone nationale et ce sont les terminaux qui sont à l’origine de la majeure partie de cet impact (80%).
Certains efforts ont pu être constatés pour réduire l’empreinte carbone du numérique. Par exemple, les émissions de gaz à effet de serre des principaux opérateurs de communications électroniques ont diminué depuis 2018. En effet, la réduction de leurs émissions directes grâce à l’optimisation des flottes de véhicules de société et l’amélioration de l’efficacité énergétique notamment, a plus que compensé la croissance de leurs émissions indirectes, liée à la progression ininterrompue de la consommation énergétique des réseaux, avec la poursuite des déploiements et le développement des usages.
Parallèlement, le référentiel révèle que seuls 13 % des téléphones mobiles ont été achetés reconditionnés et 10% des téléviseurs principaux ont été achetés de seconde main. Il reste donc encore des leviers à activer, pour allonger la durée de vie des terminaux.
Les ambitions sont donc grandes… D’autant que, contrairement à leurs homologues humains, ces « professionnels » numériques promettraient des décisions objectives, réplicables et dénuées de tout jugement – et d’être disponibles à toute heure.
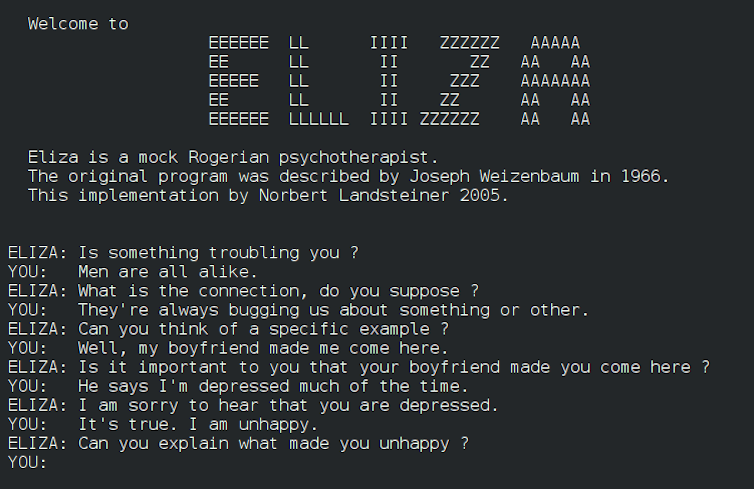
Le premier logiciel de dialogue ou chatbot est ELIZA, conçu en 1966 pour simuler un psychothérapeute.DR
Il faut cependant noter que, même si le nom de « robot-thérapeute » évoque l’image d’un robot physique, la plupart sont basés sur du texte, éventuellement des vidéos animées. En plus de cette absence de présence physique, importante pour la majorité des patients, beaucoup ne parviennent pas à reconnaître toutes les difficultés vécues par les personnes avec qui ils conversent. Comment, alors, fournir des réponses appropriées, comme l’orientation vers un service d’assistance dédié ?
Diagnostic et modèle interne chez le psychiatre
Le psychiatre, dans son entretien avec son patient, est, lui, capable de percevoir des signaux importants trahissant l’existence d’idées suicidaires ou de violences domestiques à côté desquels peuvent passer les chatbots actuels.
De même que l’ingénierie s’inspire de la nature pour concevoir des systèmes performants, il peut être pertinent d’analyser ce qu’il se passe dans la tête d’un psychiatre (la façon dont il conçoit et utilise son modèle interne) lorsqu’il pose son diagnostic pour ensuite mieux entraîner l’IA chargée de l’imiter… Mais dans quelle mesure un « modèle interne » humain et celui d’un programme sont-ils similaires ?
● La collecte d’informations et leur organisation. Lors de son entretien avec un patient, le psychiatre assemble de nombreuses informations (à partir de son dossier médical, de ses comportements, de ce qui est dit, etc.), qu’il sélectionne dans un second temps selon leur pertinence. Ces informations peuvent ensuite être associées à des profils préexistants, aux caractéristiques similaires.
Les systèmes d’IA font de même : se basant sur les données avec lesquelles ils ont été entraînés, ils extraient de leur échange avec le patient des caractéristiques (en anglais features) qu’ils sélectionnent et organisent suivant leur importance (feature selection). Ils peuvent ensuite les regrouper en profils et, ainsi, poser un diagnostic.
● La construction du modèle. Lors de leur cursus de médecine, puis tout au long de leur carrière (pratique clinique, lecture de rapports de cas, etc.), les psychiatres formulent des diagnostics dont ils connaissent l’issue. Cette formation continue renforce, dans leur modèle, les associations entre les décisions qu’ils prennent et leurs conséquences.
Ici encore, les modèles d’IA sont entraînés de la même manière : que ce soit lors de leur entraînement initial ou leur apprentissage, ils renforcent en permanence, dans leur modèle interne, les relations entre les descripteurs extraits de leurs bases de données et l’issue diagnostique. Ces bases de données peuvent être très importantes, voire contenir plus de cas qu’un clinicien n’en verra au cours de sa carrière.
● Utilisation du modèle. Au terme des deux précédentes étapes, le modèle interne du psychiatre est prêt à être utilisé pour prendre en charge de nouveaux patients. Divers facteurs extérieurs peuvent influencer la façon dont il va le faire, comme son salaire ou sa charge de travail – qui trouvent leurs équivalents dans le coût du matériel et le temps nécessaire à l’entraînement ou l’utilisation d’une IA.
Comme indiqué précédemment, il est souvent tentant de penser que le psychiatre est influencé dans sa pratique professionnelle par tout un ensemble de facteurs subjectifs, fluctuants et incertains : la qualité de sa formation, son état émotionnel, le café du matin, etc. Et qu’une IA, étant une « machine », serait débarrassée de tous ces aléas humains… C’est une erreur ! Car l’IA comporte, elle aussi, une part de subjectivité importante ; elle est simplement moins immédiatement perceptible.
[Plus de 80 000 lecteurs font confiance à la newsletter de The Conversation pour mieux comprendre les grands enjeux du monde. Abonnez-vous aujourd’hui.]
L’IA, vraiment neutre et objective ?
En effet, toute IA a été conçue par un ingénieur humain. Ainsi, si l’on veut comparer les processus de réflexion du psychiatre (et donc la conception et l’utilisation de son modèle interne) et ceux de l’IA, il faut considérer l’influence du codeur qui l’a créée. Celui-ci possède son propre modèle interne, dans ce cas non pas pour associer données cliniques et diagnostic mais type d’IA et problème à automatiser. Et là aussi, de nombreux choix techniques mais reposant sur de l’humain entrent en compte (quel système, quel algorithme de classification, etc.)
Le modèle interne de ce codeur est nécessairement influencé par les mêmes facteurs que celui du psychiatre : son expérience, la qualité de sa formation, son salaire, le temps de travail pour écrire son code, son café du matin, etc. Tous vont se répercuter sur les paramètres de conception de l’IA et donc, indirectement, sur les prises de décision de l’IA, c’est-à-dire sur les diagnostics qu’elle fera.
L’autre subjectivité qui influe sur le modèle interne des IAs est celle associée aux bases de données sur lesquelles celle-ci est entraînée. Ces bases de données sont en effet conçues, collectées et annotées par une ou plusieurs autres personnes ayant leurs propres subjectivités – subjectivité qui va jouer dans le choix des types de données collectées, du matériel impliqué, de la mesure choisie pour annoter la base de données, etc.
La subjectivité intervient non seulement chez le psychiatre humain, mais aussi chez les IAs thérapeutiques à travers les choix faits par les ingénieurs, codeurs… qui les ont conçues.Vincent Martin, Author provided
Les limites de l’IA en psychiatrie
Il ressort de ces comparaisons que l’IA n’est pas exempte de facteurs subjectifs et, de ce fait notamment, n’est pas encore prête à remplacer un « vrai » psychiatre. Ce dernier dispose, lui, d’autres qualités relationnelles et empathiques pour adapter l’utilisation de son modèle à la réalité qu’il rencontre… ce que l’IA peine encore à faire.
Le psychiatre est ainsi capable de souplesse de la collecte d’informations lors de son entretien clinique, ce qui lui permet d’accéder à des informations de temporalité très différentes : il peut par exemple interroger le patient sur un symptôme survenu des semaines auparavant ou faire évoluer son échange en temps réel en fonction des réponses obtenues. Les IAs restent pour l’heure limitées à un schéma préétabli et donc rigide.
Une autre limite forte des IAs est leur manque de corporéité, un facteur très important en psychiatrie. En effet, toute situation clinique est basée sur une rencontre entre deux personnes – et cette rencontre passe par la parole et la communication non verbale : gestes, position des corps dans l’espace, lecture des émotions sur le visage ou reconnaissance de signaux sociaux non explicites… En d’autres termes, la présence physique d’un psychiatre constitue une part importante de la relation patient-soignant, qui elle-même constitue une part importante du soin.
Est-ce à dire qu’il faut oublier l’idée d’un psy virtuel ? La comparaison entre le raisonnement du psychiatre et celui de l’IA est malgré tout intéressante dans une perspective de pédagogie croisée. En effet, bien comprendre la façon dont les psychiatres raisonnent permettra de mieux prendre en compte les facteurs intervenant dans la construction et l’utilisation des IAs dans la pratique clinique. Cette comparaison éclaire également le fait que le codeur amène lui aussi son lot de subjectivité dans les algorithmes d’IA… qui ne sont ainsi pas à même de tenir les promesses qu’on leur prête.
Ce n’est qu’à travers ce genre d’analyses qu’une véritable pratique interdisciplinaire, permettant d’hybrider l’IA et la médecine, pourra se développer à l’avenir pour le bénéfice du plus grand nombre.
L’épisode de télétravail subi au printemps 2020 a depuis laissé des traces indéniables dans les vécus mais aussi dans les attentes des salariés. Des recherches récentes ont clairement établi que ces transformations impactent et bénéficient de façon très différenciée aux salariés sur différents plans, mettant notamment en évidence des inégalités très fortes entre femmes et hommes : la santé mentale et bien-être, la répartition du travail domestique et de la charge mentale, l’emploi, le temps de travail ou encore le revenu. Elles font aussi ressortir des inégalités de nature plus socioéconomiques.
À partir d’une étude des vécus des salariés pendant la pandémie et depuis, nous interrogeons les liens entre expériences du travail et espaces de vie. Comment capturer la diversité des situations et leurs effets vécus ? Comment les employeurs peuvent-ils prendre en compte la façon dont les conditions de vie des salariés, tant au plan de leur situation personnelle, sociale, économique, familiale, vont façonner leurs expériences du télétravail ?
Pour répondre à ces questions, nous avons mené une double enquête qualitative et quantitative. Le volet qualitatif est une étude de cas portant sur 52 salariés d’une institution de formation de la métropole grenobloise, interviewés sur leur vécu de la pandémie, de mars 2020 à novembre 2021. Le volet quantitatif est constitué par une double enquête menée dans la métropole grenobloise : une première s’étant déroulée en mars 2020 durant le confinement et la seconde clôturée en janvier 2023 sur le vécu du travail post-Covid. Nos résultats mettent en évidence plusieurs constats forts et notamment la pluralité des vécus du travail durant le confinement et post-confinement.
Une transformation de la relation au travail
Pour la majorité de l’échantillon, la crise sanitaire n’a pas radicalement modifié leur vécu du travail et leur vécu relationnel. En effet, c’est plutôt la satisfaction relative par rapport à son travail et ses conditions d’emploi qui s’est légèrement amoindrie. Ceux et celles qui sont les plus touchés par une dégradation de leur satisfaction dans le travail sont ceux qui vivent mal financièrement de leur travail. Ce sont aussi les femmes, les personnes en mauvaise santé ou ceux et celles qui se sentent discriminés (par rapport à leur classe, leur origine, etc.)
Cette insatisfaction relative n’est pas liée au fait de trouver son travail utile ou inutile – à ce que l’anthropologue américain David Graeber appelait les « bullshits jobs » (« jobs à la con ») – mais cela semble davantage associé à un sentiment d’injustice salariale qui nuit aux possibilités de réalisation des personnes. Elle n’est pas liée non plus de manière générale au fait d’être en télétravail ou pas, alors même que la crise sanitaire a clairement augmenté la proportion des personnes en télétravail : avant la crise seulement 36 % des personnes de la métropole grenobloise pratiquaient au moins occasionnellement le télétravail, versus 61 % aujourd’hui.
Le retour au bureau a été vécu de manière ambivalente selon les personnes. Par exemple, parmi les personnes qui rapportent un fort désir de retour (au moins partiel) au présentiel, il y a des contrastes forts entre : des managers pour qui le présentiel est un levier de contrôle, de coordination, voire de surveillance ; des personnes pour qui le besoin relationnel était fort, et le sentiment que les liens se sont dégradés du fait du tout online ; ou encore des personnes pour qui il est important d’avoir un espace de travail dédié.
En allant plus loin dans la caractérisation de ce vécu post-Covid du télétravail, l’enquête met au jour que : (1) plus de 55 % des personnes considèrent qu’elles sont clairement plus efficaces en télétravail. La majorité des personnes semblent apprécier la flexibilité des horaires, ne plus avoir à faire le trajet domicile-travail et disent réussir à bien articuler leur vie personnelle et professionnelle ; (2) toutefois, 33 % des personnes ont un domicile mal agencé pour le télétravail et 24 % aurait sans doute des améliorations à faire dans l’agencement de leur domicile pour le télétravail ; (3) seulement 16 % disposent ainsi d’un bureau dédié dans leur logement ; (4) en outre, 62 % des personnes expriment aussi des difficultés concernant le maintien de leurs liens sociaux même si elles apprécient en majorité de ne plus être dérangées par diverses sollicitations.
Ainsi, les salariés semblent avoir adopté plutôt facilement le télétravail, même si la question du lien social interroge. Sur ce point, certaines personnes expriment toutefois des besoins spécifiques en termes relationnels, qui pourraient notamment être liés à un handicap ou une neuroatypie. Cet extrait d’entretien illustre en quoi le télétravail peut alors être ressourçant :
« Ça fait longtemps que je sais que pour moi, la configuration de travail idéale, c’est de ne voir personne de ma journée. […] Les interactions sociales pour moi sont épuisantes, je suis une personnalité introvertie, je sais que quand je vois trop de monde, trop souvent, trop longtemps, je suis vidée. […] Ça a quand même joué un rôle de révélateur. »
L’impact du lieu de vie
Un point que nous relevons dans nos analyses, c’est que les personnes interviewées et leurs récits soulignent l’influence de la classe sociale et du degré de privilège socio-économique. Les salariés rencontrés peuvent parfois euphémiser en parlant de la « chance qu’ils ont », et soulignent surtout l’impact de leur lieu de vie en termes de santé mentale et de bien-être. Le fait d’avoir un jardin permet par exemple de faire du sport, de prendre soin de soi.
L’accès à la nature et à des espaces extérieurs est en outre souligné par les interviewés comme une ressource forte. On retrouve ici le phénomène du « malheur urbain » décrit par la littérature académique. Les habitants des zones peu denses sont ainsi dans l’ensemble beaucoup plus satisfaits de leur espace de vie.
Nous faisons également émerger de nos analyses un effet préjudiciable du lieu de vie sur l’activité professionnelle, qui est cette fois exprimé par les personnes qui ont des espaces de vie plus précaires, comme nous le confie une personne interrogée :
« Il y a beaucoup de distractions, il y a la télé, juste à côté. […] J’habite dans un studio maintenant et […] c’est une pièce, donc il y a la cuisine là-bas, il y a la télé, il y a mon bureau et il y a le canapé. Donc c’est très bien pour vivre, mais pas forcément […] pour travailler et vivre en même temps… ».
Le lieu de vie peut donc être un obstacle ou une ressource de l’activité professionnelle.
Notre étude met également au jour des vécus divers et des stratégies différentes pour faire face aux responsabilités familiales et à la charge relationnelle qui ont pu croître du fait des confinements, et du travail à la maison généralisé.
La majorité des enquêtés déclarent que la crise sanitaire n’a pas changé leur relation avec leur entourage. 20 % ont toutefois vu leur situation avec leurs proches se dégrader et 9 % leur situation s’améliorer. En ce qui concerne la partition des tâches domestiques et familiales, la tendance est à la persistance du même, ce qui signifie que la crise n’a pas vraiment amélioré les inégalités hommes-femmes en la matière. Ainsi, post-pandémie, les inégalités dans les répartitions des tâches du foyer demeurent, ce qui peut être un frein pour se réaliser sur d’autres plans (travail, loisirs, engagements solidaires).
L’équilibre des temps demeure donc délicat et la période post-pandémie a accru la flexibilité sans réellement répondre aux aspirations d’une partition différente entre temps de travail, temps pour les proches, pour le loisir et l’engagement, ni d’un meilleure équité hommes-femmes.
Par conséquent, dans un contexte d’inflation marquée, de quête de performance accrue et d’hyper flexibilité, le vécu du travail post-pandémie remet sur la table la question de la responsabilité de l’employeur sur le plan de la qualité de vie (monétaire et non monétaire) de ses employés.
Avec un recours démocratisé au télétravail, le bureau vient se loger à la maison et le partage déjà flou entre espace de vie et espace de travail est remis au cœur des débats. Plutôt que de tracer une limite étanche entre la sphère professionnelle et la sphère personnelle, notre recherche suggère donc la nécessité pour les entreprises de développer une approche plus transversale de la question du bien-être et du traitement des inégalités, et d’identifier de nouveaux leviers d’action.
Hélène Picard, Professeure Assistante au département Homme, Organisations et Société. Chaire Territoires en Transitions et Chaire UNESCO pour une Culture de Paix Economique, Grenoble École de Management (GEM) et Fiona Ottaviani, Associate professor en en économie - Grenoble Ecole de Management, F-38000 Grenoble, France - coordinatrice recherche Chaire Unesco pour une culture de paix économique - co-titulaire Chaire Territoires en Transition, Grenoble École de Management (GEM)













{kind=link}