Mémoire, attention : est-il plus difficile de lire sur écran ?

Par Xavier Aparicio, Université Paris-Est Créteil Val de Marne (UPEC) et Ugo Ballenghein, Université Paris-Est Créteil Val de Marne (UPEC)
Du papyrus au papier, en passant par le parchemin et en arrivant aujourd’hui aux écrans, les supports de lecture ont évolué au fil des époques et continuent à se diversifier dans une société qui se digitalise toujours plus. Des smartphones aux tablettes ou aux liseuses, l’écrit est au cœur de nos activités quotidiennes et nos habitudes de lecture évoluent.
Les évolutions rapides de ces outils numériques invitent à s’interroger sur la manière dont on apprend à lire aujourd’hui et à se demander si l’utilisation de nouveaux supports modifie notre capacité de compréhension, qui peut se définir comme l’activité par laquelle les individus vont acquérir et utiliser des connaissances. Complexe et dynamique, elle fait intervenir différentes sources d’informations.
Les mécanismes de la compréhension de texte
Comprendre suppose d’élaborer une représentation basée sur une interprétation des informations textuelles mise en relation avec nos connaissances antérieures. Le modèle de compréhension de texte de Kintsch & van Dijk formalise trois niveaux de représentation :
le premier, niveau de surface, correspond à notre capacité à nous rappeler d’un mot lu dans le texte, sans que le sens ne soit pris en compte ;
le deuxième niveau correspond à l’intégration du sens des phrases de façon indépendante ;
enfin, le troisième niveau, appelé le modèle de situation, rend compte de la capacité du lecteur à élaborer une représentation qui est le produit de l’interaction entre ce qu’il lit et ses connaissances antérieures. C’est la capacité à produire des inférences.
Prenons un exemple pour comprendre ce que sont ces inférences. Imaginez que vous deviez répondre à la question « Où Anaïs et Julien se trouvent-ils ? » dans le texte qui suit : « Samedi, Anaïs et Julien ont vu des lions et des tigres ». La première inférence qui émerge à la lecture de cette phrase grâce à nos connaissances est très probablement le zoo. Ajoutons maintenant la phrase « Puis le clown les a beaucoup fait rire ». L’inférence produite suite à la lecture de la phrase initiale doit être inhibée, au profit d’une nouvelle inférence situant nos deux protagonistes probablement au cirque. Concluons à présent le texte avec la phrase « Maman leur a alors demandé d’éteindre la télévision pour aller se coucher ». Là encore, une nouvelle inférence est mise en place : ils étaient chez eux depuis le début.
Comprendre suppose donc la mise en place de différents traitements cognitifs en parallèle : mémoire, flexibilité mentale, mise à jour des informations, inhibition.
La fatigue du « scrolling »
D’une manière générale, nous pouvons intuitivement considérer que lire sur écran ou sur papier ne modifie pas notre capacité à comprendre un texte : indépendamment du support, il s’agit toujours de décoder des signes graphiques pour leur attribuer une signification. Toutefois, la lecture sur écran suppose de prendre en considération les caractéristiques ergonomiques des supports de lecture (taille, luminosité, contraste, etc.) et les caractéristiques du lecteur.
Une récente méta-analyse qui propose la compilation des résultats de 44 études menées auprès de plus de 170 000 participants portant sur les effets du numérique sur la lecture nous indique que, globalement, la compréhension est négativement impactée par la lecture sur support numérique comparé à la lecture sur papier. Les études ne permettent pas d’identifier de différence entre les deux supports en termes de compréhension dans le cas où on consulte des textes en pleine page (sans faire défiler le texte).
En effet, lorsque nous lisons sur écran, nous utilisons un procédé de « scrolling » qui consiste à faire défiler verticalement le texte, ce qui n’est pas sans conséquence sur notre capacité à comprendre les informations lues. Il est très difficile de retrouver une information, un mot ou une phrase, après avoir fait défiler le texte : les mots n’apparaissent plus à la même place alors que, sur papier, leur position spatiale ne change pas. Le « scrolling » perturbe le fonctionnement de notre mémoire spatiale. Le repérage de la position des mots dans le texte (codage spatial des mots) est notamment utile pour revenir rapidement sur les mots du texte, processus indispensable pour la compréhension.
D’autre part, le rétroéclairage des écrans sur lesquels nous lisons, qui implique la projection d’une source lumineuse vers l’utilisateur, n’est pas sans conséquence sur notre capacité à lire les informations. Plusieurs études ont mis en évidence son effet néfaste sur la lecture.
La capacité de prise d’information visuelle est réduite sur écran et nécessite davantage de fixations oculaires lors de lecture des textes. Il en résulte une fatigue visuelle accrue, associée à différents symptômes (maux de tête, migraines chroniques, etc.), notamment lorsque l’activité de lecture est prolongée ou effectuée sur des interfaces de mauvaise qualité (avec un mauvais contraste entre fond et couleur, des interlignes réduits renforçant l’encombrement visuel). Ces effets délétères ne sont pas répertoriés sur les liseuses, qui ne sont pas rétroéclairées mais disposent d’une encre électronique.
Sur Internet, une lecture superficielle ?
Pour le lecteur adulte, la lecture est une activité automatique et rapide car l’apprentissage systématique de la correspondance entre les graphèmes (lettres, groupes de lettres) et les phonèmes (sons) et le développement du lexique mental permettent notamment de libérer des ressources cognitives nécessaires à la mise en place du processus de compréhension. Notre vitesse de lecture varie en fonction de l’objectif de lecture que nous nous sommes fixé.
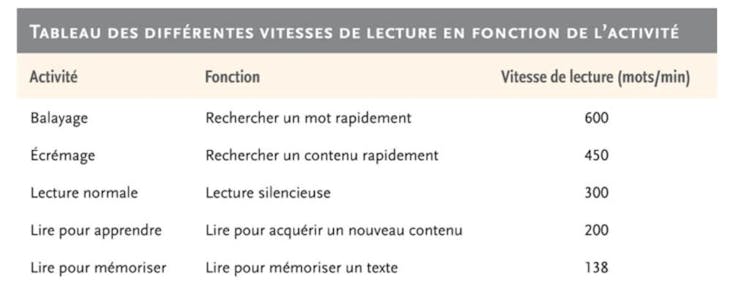
Lorsque l’on navigue sur des pages web, notre lisons des pages riches en informations, véhiculant des messages parfois très courts et dynamiques destinés à être plus accessibles en termes de quantité de contenu et donc de rapidité de lecture. Cela donne un côté superficiel à la lecture, qui devient un écrémage.
Cette lecture superficielle correspond davantage à une recherche d’information qu’à une lecture approfondie visant à comprendre un concept par exemple. L’attention est notamment perturbée par la présence de fenêtres multiples, l’apparition de notifications, la présence de liens hypertextes qui vont nous permettre de naviguer mais vont aussi contribuer à nous désorienter face au flux conséquent d’informations présentes.
Une grande quantité d’informations accessibles ne facilite pas l’extraction des informations nécessaires à la prise de décision, et peut même conduire à une surcharge cognitive conduisant le lecteur à ne plus être capable de traiter efficacement les informations. C’est le principe de la loi de Hick : le temps qu’il faut à un utilisateur pour prendre une décision augmente en fonction du nombre de choix à sa disposition.
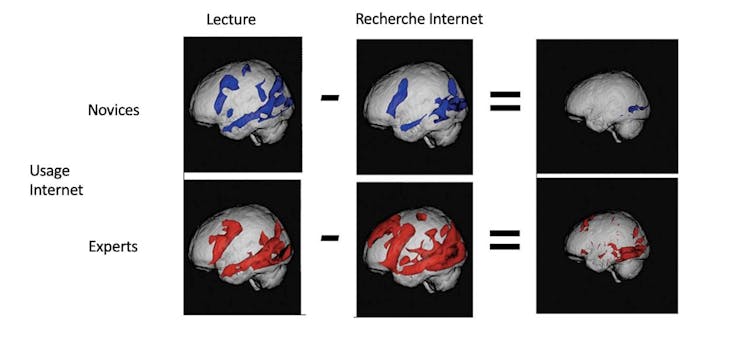
Une étude réalisée par Gary W.Small et ses co-auteurs s’est intéressée aux modifications cérébrales associées à l’usage d’internet. L’objectif était de comparer les zones cérébrales activées chez des utilisateurs experts et novices d’internet, en leur demandant d’effectuer des activités de lecture ou de recherche d’information.
Les données issues de l’imagerie cérébrale montrent que lors de la lecture de texte, les zones cérébrales activées (contrôlant le langage, la mémoire et la vision) sont similaires quel que soit le niveau d’expertise Internet. Par contre, lors de la recherche d’information, des zones supplémentaires sont activées chez les experts : celles des régions contrôlant la prise de décision et le raisonnement complexe.
En conclusion, si l’utilisation des outils numériques présente des avantages indéniables, des améliorations ergonomiques semblent nécessaires pour optimiser les supports de lecture et les rendre plus compatibles avec les aptitudes cognitives des lecteurs. À titre d’exemple, les filtres anti-lumière bleue, supposés diminuer les effets de fatigue associés à l’utilisation des écrans, ont une efficacité contrastée. Nul doute que les recherches, nombreuses, sur une technologie en évolution rapide, nous apporteront ces prochaines années de nouvelles données sur l’influence des écrans sur notre capacité de lecture.![]()
Xavier Aparicio, Maître de conférences HDR en psychologie cognitive, Université Paris-Est Créteil Val de Marne (UPEC) et Ugo Ballenghein, Maître de conférences en psychologie cognitive, Université Paris-Est Créteil Val de Marne (UPEC)
Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original.